NegoA.00164.a
arginyl-tRNA synthetase
| CENTER ID: | NegoA.00164.a |
| ORGANISM: | Neisseria gonorrhoeae NCCP11945 |
| ASSOCIATED DISEASE: | |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | True |
| NIH RISK GROUP: | 2 |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
I/II |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Clones*
| CENTER REFERENCE ID |
DOMAIN/REGION DESCRIPTION |
INFO | AA START |
AA STOP |
ORDER MATERIAL |
|---|---|---|---|---|---|
| NegoA.00164.a.B1.GE39957 | full length | 1 | 572 |
* SSGCID clones represent un-induced expression constructs which have been verified by sequencing from vector primers. Clones may contain a tag, such as N-term 6xHis. Get sequence information
using the button in the "info" column.
Proteins
| CENTER REFERENCE ID |
DOMAIN/REGION DESCRIPTION |
INFO | AA START |
AA STOP |
ORDER MATERIAL |
|---|---|---|---|---|---|
| NegoA.00164.a.B1.PS38233 | full length | 1 | 572 |
Structures
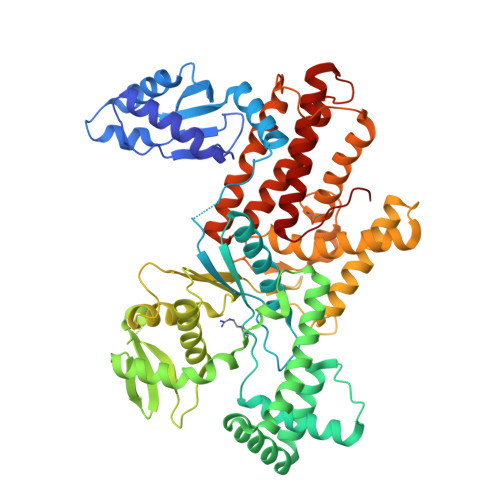
6AO8
DEPOSITED: 8/15/2017
DETERMINATION: XRay
CLONE: NegoA.00164.a.B1.GE39957
PROTEIN: NegoA.00164.a.B1.PS38233
External Resources
| RESOURCE | REFERENCE ID |
|---|---|
| BV-BRC: | fig|521006.8.peg.898 |
| UniProt: | B4RL22 |
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MNLHQTVEHE AAAAFAAAGI AGSPVVLQPT KNAEHGDFQI NGVMGAAKKA KQNPRELAQK VADALAGNAV IESAEVAGPG FINLRLRHEF LAQNIHAALN DARFGVAKTA QPQTVVIDYS SPNLAKEMHV GHLRSSIIGD SISRVLEFTG NTVIRQNHVG DWGTQFGMLV AYLVEQQKDN AAFELADLEQ FYRAAKVRFD EDPAFADTAR EYVVKLQGGD ETVLALWKQF VDISLSHAQA VYDTLGLKLR PEDVAGESKY NDDLQPVADD LVQKGLAVED DGAKVVFLDE FKNKEGEPAA FIVQKQGGGF LYASTDLACL RYRVGRLKAD RLLYVVDHRQ ALHFEQLFTT SRKAGYLPEN AKAEFIGFGT MMGKDGKPFK TRSGDTVKLV DLLTEAVERA TALVKEKNPE LGADEAAKIG KTVGIGAVKY ADLSKNRTSD YVFDWDAMLS FEGNTAPYLQ YAYTRVQSVF RKAGEWDATA PTVLTEPLEK QLAAELLKFE NVLQSVADTA YPHYLAAYLY QAATLFSRFY EACPILKAEG ASRNSRLQLA KLTGNTLKQG LDLLGIDVLD VM
NT Sequence
ATGAACCTAC ATCAAACCGT CGAACACGAA GCCGCCGCCG CCTTTGCCGC CGCAGGCATC GCCGGCAGCC CCGTTGTCTT GCAGCCGACC AAAAATGCCG AACACGGCGA TTTCCAAATC AACGGCGTGA TGGGTGCGGC GAAAAAAGCC AAACAAAATC CGCGCGAACT GGCGCAAAAG GTCGCCGACG CATTGGCGGG CAACGCCGTC ATCGAAAGCG CGGAAGTGGC CGGACCCGGC TTTATCAACC TGCGCCTGCG CCACGAATTT CTCGCTCAAA ACATTCATGC GGCTTTGAAC GACGCGCGTT TCGGCGTAGC GAAAACTGCC CAACCGCAAA CCGTCGTTAT CGACTATTCT TCGCCTAATC TGGCGAAGGA AATGCACGTC GGCCATCTGC GCTCCAGCAT CATTGGCGAC AGCATTTCAC GCGTGTTGGA ATTTACGGGC AACACCGTCA TCCGCCAAAA CCATGTCGGC GACTGGGGTA CGCAGTTCGG CATGTTGGTT GCTTATTTGG TCGAGCAGCA GAAAGACAAT GCCGCGTTCG AGCTGGCGGA TTTGGAGCAG TTTTACCGCG CCGCCAAAGT GCGCTTTGAC GAAGACCCTG CCTTTGCCGA CACCGCGCGC GAATACGTTG TGAAGCTGCA AGGCGGCGAT GAAACCGTGT TGGCGTTGTG GAAACAGTTT GTCGATATTT CGCTCTCGCA CGCCCAAGCC GTTTACGACA CGCTGGGCTT GAAGCTGCGC CCCGAAGATG TGGCGGGCGA ATCGAAATAC AACGACGATT TGCAGCCTGT AGCCGATGAT TTGGTTCAAA AAGGCCTGGC GGTTGAGGAC GACGGCGCGA AAGTCGTGTT CTTGGACGAG TTTAAAAACA AAGAAGGCGA ACCCGCCGCA TTTATCGTGC AAAAACAAGG CGGCGGCTTC CTTTATGCCT CCACCGACTT GGCGTGCCTG CGCTACCGCG TCGGCCGTCT CAAAGCCGAC CGCCTGCTGT ACGTCGTCGA CCACCGCCAA GCCCTGCACT TCGAGCAACT CTTTACCACT TCCCGCAAAG CAGGCTATCT GCCTGAAAAT GCAAAAGCCG AGTTTATCGG CTTCGGCACC ATGATGGGCA AAGACGGCAA ACCGTTCAAA ACGCGCAGCG GCGACACCGT AAAACTGGTT GACCTGCTGA CCGAAGCCGT CGAGCGCGCC ACCGCTTTGG TGAAAGAAAA AAATCCCGAA TTGGGCGCGG ATGAAGCCGC CAAAATCGGC AAGACCGTCG GCATCGGCGC AGTCAAATAC GCCGATTTAA GCAAAAACCG CACCAGCGAT TATGTGTTCG ACTGGGACGC CATGCTCTCA TTTGAAGGCA ACACCGCCCC CTACCTGCAA TACGCCTACA CCCGCGTGCA AAGCGTGTTC CGCAAAGCCG GAGAATGGGA CGCAACCGCA CCGACCGTTT TGACCGAACC ACTGGAAAAA CAGCTTGCCG CCGAGCTTCT GAAATTTGAA AACGTGCTGC AAAGCGTGGC GGACACCGCG TATCCGCACT ACCTCGCCGC CTACCTTTAC CAAGCCGCCA CCCTGTTCAG CCGCTTCTAC GAAGCTTGCC CGATTTTGAA AGCCGAAGGC GCAAGCCGCA ACAGCCGCCT GCAACTGGCA AAACTCACCG GCAACACGCT GAAACAAGGC TTGGATTTGC TGGGCATCGA TGTGTTGGAC GTAATGTAA
Details for NegoA.00164.a.B1.GE39957
| HARVESTED ON: | 2/26/2016 |
| SEQUENCED ON: | 8/9/2017 |
| EXPECTED MW: | 64kDa |
| OBSERVED MW: | 64kDa |
| ANTIBIOTIC MARKER: | ampicillin |
| COUNT OF EXPRESSION COLONIES: | Many (50-100) |
| TOTAL EXPRESSION LEVEL: | High Expression |
| SOLUBLE EXPRESSION LEVEL | Low Expression |
| EXPRESSION HOST: | data unavailable |
| SEQUENCING RESULT: | pass with sequence variation |
| PERCENT IDENTITY: | 99 |
| PERCENT COVERAGE: | 100 |
Validated AA Sequence
MAHHHHHHMN LHQTVEHEAA AAFAAAGIAG SPVVLQPTKN AEHGDFQING VMGAAKKAKQ NPRELAQKVA DALAGNAVIE SAEVAGPGFI NLRLRHEFLA QNIHAALNDA RFGVAKTAQP QTVVIDYSSP NLAKEMHVGH LRSSIIGDSI SRVLEFTGNT VIRQNHVGDW GTQFGMLVAY LVEQQKDNAA FELADLEQFY RAAXVRFDED PAFADTAREY VVKLQGGDET VLALWKQFVD ISLSHAQAVY DTLGLKLRPE DVAGESKYND DLQPVADDLV QKGLAVEDDG AKVVFLDEFK NKEGEPAAFI VQKQGGGFLY ASTDLACLRY RIGRLKAGRL LYVVDHRQAL HFEQLFTTSR KAGYLPEDAK AEFIGFGTMM GKDGKPFKTR SGDTVKLVDL LTEAVERATA LVKEKNPELG ADEAAKIGKT VGIGAVKYAD LSKNRTSDYV FDWDAMLSFE GNTAPYLQYA YTRVQSVFRK AGEWDATAPT VLTEPLEKQL AAELLKFENV LQSVADTAYP HYLAAYLYQA ATLFSRFYEA CPILKAEGAS RNSRLQLAKL TGNTLKQGLD LLGIDVLDVM
Validated NT Sequence
atggctcacc accaccacca ccatatgaac ctacatcaaa ccgtcgaaca cgaagccgcc gccgcctttg ccgccgcagg catcgccggc agccccgttg tcttgcagcc gaccaaaaat gccgagcacg gcgatttcca aatcaacggc gtgatgggtg cggcgaaaaa agccaaacaa aatccgcgcg aactggcgca aaaggtcgcc gacgcattgg cgggcaacgc cgtcatcgaa agcgcggaag tggccggacc cggctttatc aacctgcgcc tgcgccacga atttctcgct caaaacattc atgcggcttt gaacgatgcg cgtttcggcg tagcgaaaac tgcccaaccg caaaccgtcg tcatcgacta ttcctcgccc aatctggcga aggaaatgca cgtcggccat ctgcgttcca gcatcatcgg cgacagtatt tcgcgcgtgt tggaatttac gggcaacacc gttatccgtc aaaaccacgt cggcgactgg ggtacgcagt tcggcatgtt ggtcgcttat ttggtcgagc agcaaaaaga caatgccgcg ttcgagctgg cggatttgga gcagttttac cgcgccgccn aagtgcgctt tgacgaagac cctgcctttg ccgacaccgc acgcgaatac gttgtgaagc tgcaaggcgg cgatgaaacc gtgttggcgt tgtggaaaca gtttgtcgat atttcgctct cgcacgccca agccgtttac gacacgctgg gcttgaagct gcgccccgaa gacgtggcgg gcgaatcgaa atacaacgac gatttgcagc ccgtagccga tgatttggtt caaaaaggcc tggcggttga ggacgacggc gcgaaagtcg tgttcttgga cgagttcaaa aacaaagagg gcgaacctgc cgcatttatc gtgcaaaaac aaggcggcgg cttcctttat gcttccaccg atttggcgtg cctgcgctac cgcataggcc gtctgaaagc cggccgcctg ctgtacgtcg tcgaccaccg ccaagccctg cacttcgaac aacttttcac cacttcccgc aaagcaggct atctgcctga agatgcaaaa gccgagttta tcggcttcgg caccatgatg ggcaaagacg gcaaaccgtt caaaacgcgc agcggcgaca ccgtaaaact ggttgacctg ctgaccgaag ccgtcgagcg cgccaccgct ttggtgaaag aaaaaaatcc cgaattgggc gcggatgaag ccgccaaaat cggcaagacc gtcggcatcg gcgcagtcaa atacgccgac ttgagcaaaa accgcaccag cgattatgtg ttcgactggg acgccatgct ctcatttgaa ggcaacaccg ccccctacct gcaatacgcc tacacccgcg tgcaaagcgt gttccgcaaa gccggagaat gggacgcaac cgcaccgacc gttttgaccg aaccactgga aaaacagctt gccgccgagc ttctgaaatt tgaaaacgtg ctgcaaagcg tggcggacac cgcgtatccg cactacctcg ccgcctacct ttaccaagcc gccaccctgt tcagccgctt ctacgaagct tgtccgattt tgaaagccga aggcgcaagc cgcaacagcc gcctgcaact ggcaaaactc accggcaaca cgctgaaaca aggcttggat ttgctgggca tcgatgtgtt ggacgtaatg taa
Expected Protein Sequence
MAHHHHHHMN LHQTVEHEAA AAFAAAGIAG SPVVLQPTKN AEHGDFQING VMGAAKKAKQ NPRELAQKVA DALAGNAVIE SAEVAGPGFI NLRLRHEFLA QNIHAALNDA RFGVAKTAQP QTVVIDYSSP NLAKEMHVGH LRSSIIGDSI SRVLEFTGNT VIRQNHVGDW GTQFGMLVAY LVEQQKDNAA FELADLEQFY RAAKVRFDED PAFADTAREY VVKLQGGDET VLALWKQFVD ISLSHAQAVY DTLGLKLRPE DVAGESKYND DLQPVADDLV QKGLAVEDDG AKVVFLDEFK NKEGEPAAFI VQKQGGGFLY ASTDLACLRY RVGRLKADRL LYVVDHRQAL HFEQLFTTSR KAGYLPENAK AEFIGFGTMM GKDGKPFKTR SGDTVKLVDL LTEAVERATA LVKEKNPELG ADEAAKIGKT VGIGAVKYAD LSKNRTSDYV FDWDAMLSFE GNTAPYLQYA YTRVQSVFRK AGEWDATAPT VLTEPLEKQL AAELLKFENV LQSVADTAYP HYLAAYLYQA ATLFSRFYEA CPILKAEGAS RNSRLQLAKL TGNTLKQGLD LLGIDVLDVM
Full NT Sequence (Expression Vector + Insert)
taatacgact cactataggg agaccacaac ggtttccctc tagaaataat tttgtttaac tttaagaagg agatatacca tggctcacca ccaccaccac catatgaacc tacatcaaac cgtcgaacac gaagccgccg ccgcctttgc cgccgcaggc atcgccggca gccccgttgt cttgcagccg accaaaaatg ccgaacacgg cgatttccaa atcaacggcg tgatgggtgc ggcgaaaaaa gccaaacaaa atccgcgcga actggcgcaa aaggtcgccg acgcattggc gggcaacgcc gtcatcgaaa gcgcggaagt ggccggaccc ggctttatca acctgcgcct gcgccacgaa tttctcgctc aaaacattca tgcggctttg aacgacgcgc gtttcggcgt agcgaaaact gcccaaccgc aaaccgtcgt tatcgactat tcttcgccta atctggcgaa ggaaatgcac gtcggccatc tgcgctccag catcattggc gacagcattt cacgcgtgtt ggaatttacg ggcaacaccg tcatccgcca aaaccatgtc ggcgactggg gtacgcagtt cggcatgttg gttgcttatt tggtcgagca gcagaaagac aatgccgcgt tcgagctggc ggatttggag cagttttacc gcgccgccaa agtgcgcttt gacgaagacc ctgcctttgc cgacaccgcg cgcgaatacg ttgtgaagct gcaaggcggc gatgaaaccg tgttggcgtt gtggaaacag tttgtcgata tttcgctctc gcacgcccaa gccgtttacg acacgctggg cttgaagctg cgccccgaag atgtggcggg cgaatcgaaa tacaacgacg atttgcagcc tgtagccgat gatttggttc aaaaaggcct ggcggttgag gacgacggcg cgaaagtcgt gttcttggac gagtttaaaa acaaagaagg cgaacccgcc gcatttatcg tgcaaaaaca aggcggcggc ttcctttatg cctccaccga cttggcgtgc ctgcgctacc gcgtcggccg tctcaaagcc gaccgcctgc tgtacgtcgt cgaccaccgc caagccctgc acttcgagca actctttacc acttcccgca aagcaggcta tctgcctgaa aatgcaaaag ccgagtttat cggcttcggc accatgatgg gcaaagacgg caaaccgttc aaaacgcgca gcggcgacac cgtaaaactg gttgacctgc tgaccgaagc cgtcgagcgc gccaccgctt tggtgaaaga aaaaaatccc gaattgggcg cggatgaagc cgccaaaatc ggcaagaccg tcggcatcgg cgcagtcaaa tacgccgatt taagcaaaaa ccgcaccagc gattatgtgt tcgactggga cgccatgctc tcatttgaag gcaacaccgc cccctacctg caatacgcct acacccgcgt gcaaagcgtg ttccgcaaag ccggagaatg ggacgcaacc gcaccgaccg ttttgaccga accactggaa aaacagcttg ccgccgagct tctgaaattt gaaaacgtgc tgcaaagcgt ggcggacacc gcgtatccgc actacctcgc cgcctacctt taccaagccg ccaccctgtt cagccgcttc tacgaagctt gcccgatttt gaaagccgaa ggcgcaagcc gcaacagccg cctgcaactg gcaaaactca ccggcaacac gctgaaacaa ggcttggatt tgctgggcat cgatgtgttg gacgtaatgt gagtaagata ggatccggct gctaacaaag cccgaaagga agctgagttg gctgctgcca ccgctgagca ataactagca taaccccttg gggcctctaa acgggtcttg aggggttttt tgctgaaagg aggaactata tccggatatc cacaggacgg gtgtggtcgc catgatcgcg tagtcgatag tggctccaag tagcgaagcg agcaggactg ggcggcggcc aaagcggtcg gacagtgctc cgagaacggg tgcgcataga aattgcatca acgcatatag cgctagcagc acgccatagt gactggcgat gctgtcggaa tggacgatat cccgcaagag gcccggcagt accggcataa ccaagcctat gcctacagca tccagggtga cggtgccgag gatgacgatg agcgcattgt tagatttcat acacggtgcc tgactgcgtt agcaatttaa ctgtgataaa ctaccgcatt aaagcttatc gatgataagc tgtcaaacat gagaattctt gaagacgaaa gggcctcgtg atacgcctat ttttataggt taatgtcatg ataataatgg tttcttagac gtcaggtggc acttttcggg gaaatgtgcg cggaacccct atttgtttat ttttctaaat acattcaaat atgtatccgc tcatgagaca ataaccctga taaatgcttc aataatattg aaaaaggaag agtatgagta ttcaacattt ccgtgtcgcc cttattccct tttttgcggc attttgcctt cctgtttttg ctcacccaga aacgctggtg aaagtaaaag atgctgaaga tcagttgggt gcacgagtgg gttacatcga actggatctc aacagcggta agatccttga gagttttcgc cccgaagaac gttttccaat gatgagcact tttaaagttc tgctatgtgg cgcggtatta tcccgtgttg acgccgggca agagcaactc ggtcgccgca tacactattc tcagaatgac ttggttgagt actcaccagt cacagaaaag catcttacgg atggcatgac agtaagagaa ttatgcagtg ctgccataac catgagtgat aacactgcgg ccaacttact tctgacaacg atcggaggac cgaaggagct aaccgctttt ttgcacaaca tgggggatca tgtaactcgc cttgatcgtt gggaaccgga gctgaatgaa gccataccaa acgacgagcg tgacaccacg atgcctgcag caatggcaac aacgttgcgc aaactattaa ctggcgaact acttactcta gcttcccggc aacaattaat agactggatg gaggcggata aagttgcagg accacttctg cgctcggccc ttccggctgg ctggtttatt gctgataaat ctggagccgg tgagcgtggg tctcgcggta tcattgcagc actggggcca gatggtaagc cctcccgtat cgtagttatc tacacgacgg ggagtcaggc aactatggat gaacgaaata gacagatcgc tgagataggt gcctcactga ttaagcattg gtaactgtca gaccaagttt actcatatat actttagatt gatttaaaac ttcattttta atttaaaagg atctaggtga agatcctttt tgataatctc atgaccaaaa tcccttaacg tgagttttcg ttccactgag cgtcagaccc cgtagaaaag atcaaaggat cttcttgaga tccttttttt ctgcgcgtaa tctgctgctt gcaaacaaaa aaaccaccgc taccagcggt ggtttgtttg ccggatcaag agctaccaac tctttttccg aaggtaactg gcttcagcag agcgcagata ccaaatactg tccttctagt gtagccgtag ttaggccacc acttcaagaa ctctgtagca ccgcctacat acctcgctct gctaatcctg ttaccagtgg ctgctgccag tggcgataag tcgtgtctta ccgggttgga ctcaagacga tagttaccgg ataaggcgca gcggtcgggc tgaacggggg gttcgtgcac acagcccagc ttggagcgaa cgacctacac cgaactgaga tacctacagc gtgagctatg agaaagcgcc acgcttcccg aagggagaaa ggcggacagg tatccggtaa gcggcagggt cggaacagga gagcgcacga gggagcttcc agggggaaac gcctggtatc tttatagtcc tgtcgggttt cgccacctct gacttgagcg tcgatttttg tgatgctcgt caggggggcg gagcctatgg aaaaacgcca gcaacgcggc ctttttacgg ttcctggcct tttgctggcc ttttgctcac atgttctttc ctgcgttatc ccctgattct gtggataacc gtattaccgc ctttgagtga gctgataccg ctcgccgcag ccgaacgacc gagcgcagcg agtcagtgag cgaggaagcg gaagagcgcc tgatgcggta ttttctcctt acgcatctgt gcggtatttc acaccgcata tatggtgcac tctcagtaca atctgctctg atgccgcata gttaagccag tatacactcc gctatcgcta cgtgactggg tcatggctgc gccccgacac ccgccaacac ccgctgacgc gccctgacgg gcttgtctgc tcccggcatc cgcttacaga caagctgtga ccgtctccgg gagctgcatg tgtcagaggt tttcaccgtc atcaccgaaa cgcgcgaggc agctgcggta aagctcatca gcgtggtcgt gaagcgattc acagatgtct gcctgttcat ccgcgtccag ctcgttgagt ttctccagaa gcgttaatgt ctggcttctg ataaagcggg ccatgttaag ggcggttttt tcctgtttgg tcactgatgc ctccgtgtaa gggggatttc tgttcatggg ggtaatgata ccgatgaaac gagagaggat gctcacgata cgggttactg atgatgaaca tgcccggtta ctggaacgtt gtgagggtaa acaactggcg gtatggatgc ggcgggacca gagaaaaatc actcagggtc aatgccagcg cttcgttaat acagatgtag gtgttccaca gggtagccag cagcatcctg cgatgcagat ccggaacata atggtgcagg gcgctgactt ccgcgtttcc agactttacg aaacacggaa accgaagacc attcatgttg ttgctcaggt cgcagacgtt ttgcagcagc agtcgcttca cgttcgctcg cgtatcggtg attcattctg ctaaccagta aggcaacccc gccagcctag ccgggtcctc aacgacagga gcacgatcat gcgcacccgt ggccaggacc caacgctgcc cgagatgcgc cgcgtgcggc tgctggagat ggcggacgcg atggatatgt tctgccaagg gttggtttgc gcattcacag ttctccgcaa gaattgattg gctccaattc ttggagtggt gaatccgtta gcgaggtgcc gccggcttcc attcaggtcg aggtggcccg gctccatgca ccgcgacgca acgcggggag gcagacaagg tatagggcgg cgcctacaat ccatgccaac ccgttccatg tgctcgccga ggcggcataa atcgccgtga cgatcagcgg tccagtgatc gaagttaggc tggtaagagc cgcgagcgat ccttgaagct gtccctgatg gtcgtcatct acctgcctgg acagcatggc ctgcaacgcg ggcatcccga tgccgccgga agcgagaaga atcataatgg ggaaggccat ccagcctcgc gtcgcgaacg ccagcaagac gtagcccagc gcgtcggccg ccatgccggc gataatggcc tgcttctcgc cgaaacgttt ggtggcggga ccagtgacga aggcttgagc gagggcgtgc aagattccga ataccgcaag cgacaggccg atcatcgtcg cgctccagcg aaagcggtcc tcgccgaaaa tgacccagag cgctgccggc acctgtccta cgagttgcat gataaagaag acagtcataa gtgcggcgac gatagtcatg ccccgcgccc accggaagga gctgactggg ttgaaggctc tcaagggcat cggtcgacgc tctcccttat gcgactcctg cattaggaag cagcccagta gtaggttgag gccgttgagc accgccgccg caaggaatgg tgcatgcaag gagatggcgc ccaacagtcc cccggccacg gggcctgcca ccatacccac gccgaaacaa gcgctcatga gcccgaagtg gcgagcccga tcttccccat cggtgatgtc ggcgatatag gcgccagcaa ccgcacctgt ggcgccggtg atgccggcca cgatgcgtcc ggcgtagagg atcgagatct cgatcccgcg aaat
Details for NegoA.00164.a.B1.PS38233
| PURIFICATION DATe: | 3/21/2017 |
| CONCENTRATION: | 40mg/ml |
| OBSERVED MW: | 70kDa |
| EXPRESSION LEVEL: | Moderate Expression |
| PROTEIN PURIFICATION BUFFER: | 20 mM HEPES pH 7.0, 300 mM NaCl, 5% glycerol, 1 mM TCEP |
| EXPRESSION HOST: | data unavailable |
| VIAL COUNT (approx.): | 1 |
| VIAL VOLUME: | 200µl |
| PERCENT IDENTITY: | 99 |
| PERCENT COVERAGE: | 100 |
Protocol Notes
notes unavailable
Validated AA Sequence
MAHHHHHHMN LHQTVEHEAA AAFAAAGIAG SPVVLQPTKN AEHGDFQING VMGAAKKAKQ NPRELAQKVA DALAGNAVIE SAEVAGPGFI NLRLRHEFLA QNIHAALNDA RFGVAKTAQP QTVVIDYSSP NLAKEMHVGH LRSSIIGDSI SRVLEFTGNT VIRQNHVGDW GTQFGMLVAY LVEQQKDNAA FELADLEQFY RAAXVRFDED PAFADTAREY VVKLQGGDET VLALWKQFVD ISLSHAQAVY DTLGLKLRPE DVAGESKYND DLQPVADDLV QKGLAVEDDG AKVVFLDEFK NKEGEPAAFI VQKQGGGFLY ASTDLACLRY RIGRLKAGRL LYVVDHRQAL HFEQLFTTSR KAGYLPEDAK AEFIGFGTMM GKDGKPFKTR SGDTVKLVDL LTEAVERATA LVKEKNPELG ADEAAKIGKT VGIGAVKYAD LSKNRTSDYV FDWDAMLSFE GNTAPYLQYA YTRVQSVFRK AGEWDATAPT VLTEPLEKQL AAELLKFENV LQSVADTAYP HYLAAYLYQA ATLFSRFYEA CPILKAEGAS RNSRLQLAKL TGNTLKQGLD LLGIDVLDVM
Validated NT Sequence
atggctcacc accaccacca ccatatgaac ctacatcaaa ccgtcgaaca cgaagccgcc gccgcctttg ccgccgcagg catcgccggc agccccgttg tcttgcagcc gaccaaaaat gccgagcacg gcgatttcca aatcaacggc gtgatgggtg cggcgaaaaa agccaaacaa aatccgcgcg aactggcgca aaaggtcgcc gacgcattgg cgggcaacgc cgtcatcgaa agcgcggaag tggccggacc cggctttatc aacctgcgcc tgcgccacga atttctcgct caaaacattc atgcggcttt gaacgatgcg cgtttcggcg tagcgaaaac tgcccaaccg caaaccgtcg tcatcgacta ttcctcgccc aatctggcga aggaaatgca cgtcggccat ctgcgttcca gcatcatcgg cgacagtatt tcgcgcgtgt tggaatttac gggcaacacc gttatccgtc aaaaccacgt cggcgactgg ggtacgcagt tcggcatgtt ggtcgcttat ttggtcgagc agcaaaaaga caatgccgcg ttcgagctgg cggatttgga gcagttttac cgcgccgccn aagtgcgctt tgacgaagac cctgcctttg ccgacaccgc acgcgaatac gttgtgaagc tgcaaggcgg cgatgaaacc gtgttggcgt tgtggaaaca gtttgtcgat atttcgctct cgcacgccca agccgtttac gacacgctgg gcttgaagct gcgccccgaa gacgtggcgg gcgaatcgaa atacaacgac gatttgcagc ccgtagccga tgatttggtt caaaaaggcc tggcggttga ggacgacggc gcgaaagtcg tgttcttgga cgagttcaaa aacaaagagg gcgaacctgc cgcatttatc gtgcaaaaac aaggcggcgg cttcctttat gcttccaccg atttggcgtg cctgcgctac cgcataggcc gtctgaaagc cggccgcctg ctgtacgtcg tcgaccaccg ccaagccctg cacttcgaac aacttttcac cacttcccgc aaagcaggct atctgcctga agatgcaaaa gccgagttta tcggcttcgg caccatgatg ggcaaagacg gcaaaccgtt caaaacgcgc agcggcgaca ccgtaaaact ggttgacctg ctgaccgaag ccgtcgagcg cgccaccgct ttggtgaaag aaaaaaatcc cgaattgggc gcggatgaag ccgccaaaat cggcaagacc gtcggcatcg gcgcagtcaa atacgccgac ttgagcaaaa accgcaccag cgattatgtg ttcgactggg acgccatgct ctcatttgaa ggcaacaccg ccccctacct gcaatacgcc tacacccgcg tgcaaagcgt gttccgcaaa gccggagaat gggacgcaac cgcaccgacc gttttgaccg aaccactgga aaaacagctt gccgccgagc ttctgaaatt tgaaaacgtg ctgcaaagcg tggcggacac cgcgtatccg cactacctcg ccgcctacct ttaccaagcc gccaccctgt tcagccgctt ctacgaagct tgtccgattt tgaaagccga aggcgcaagc cgcaacagcc gcctgcaact ggcaaaactc accggcaaca cgctgaaaca aggcttggat ttgctgggca tcgatgtgtt ggacgtaatg taa
Expressed Protein Sequence
MAHHHHHHMN LHQTVEHEAA AAFAAAGIAG SPVVLQPTKN AEHGDFQING VMGAAKKAKQ NPRELAQKVA DALAGNAVIE SAEVAGPGFI NLRLRHEFLA QNIHAALNDA RFGVAKTAQP QTVVIDYSSP NLAKEMHVGH LRSSIIGDSI SRVLEFTGNT VIRQNHVGDW GTQFGMLVAY LVEQQKDNAA FELADLEQFY RAAKVRFDED PAFADTAREY VVKLQGGDET VLALWKQFVD ISLSHAQAVY DTLGLKLRPE DVAGESKYND DLQPVADDLV QKGLAVEDDG AKVVFLDEFK NKEGEPAAFI VQKQGGGFLY ASTDLACLRY RVGRLKADRL LYVVDHRQAL HFEQLFTTSR KAGYLPENAK AEFIGFGTMM GKDGKPFKTR SGDTVKLVDL LTEAVERATA LVKEKNPELG ADEAAKIGKT VGIGAVKYAD LSKNRTSDYV FDWDAMLSFE GNTAPYLQYA YTRVQSVFRK AGEWDATAPT VLTEPLEKQL AAELLKFENV LQSVADTAYP HYLAAYLYQA ATLFSRFYEA CPILKAEGAS RNSRLQLAKL TGNTLKQGLD LLGIDVLDVM
Full NT Sequence (Expression Vector + Insert)
TAATACGACT CACTATAGGG AGACCACAAC GGTTTCCCTC TAGAAATAAT TTTGTTTAAC TTTAAGAAGG AGATATACCA TGGCTCACCA CCACCACCAC CATATGAACC TACATCAAAC CGTCGAACAC GAAGCCGCCG CCGCCTTTGC CGCCGCAGGC ATCGCCGGCA GCCCCGTTGT CTTGCAGCCG ACCAAAAATG CCGAACACGG CGATTTCCAA ATCAACGGCG TGATGGGTGC GGCGAAAAAA GCCAAACAAA ATCCGCGCGA ACTGGCGCAA AAGGTCGCCG ACGCATTGGC GGGCAACGCC GTCATCGAAA GCGCGGAAGT GGCCGGACCC GGCTTTATCA ACCTGCGCCT GCGCCACGAA TTTCTCGCTC AAAACATTCA TGCGGCTTTG AACGACGCGC GTTTCGGCGT AGCGAAAACT GCCCAACCGC AAACCGTCGT TATCGACTAT TCTTCGCCTA ATCTGGCGAA GGAAATGCAC GTCGGCCATC TGCGCTCCAG CATCATTGGC GACAGCATTT CACGCGTGTT GGAATTTACG GGCAACACCG TCATCCGCCA AAACCATGTC GGCGACTGGG GTACGCAGTT CGGCATGTTG GTTGCTTATT TGGTCGAGCA GCAGAAAGAC AATGCCGCGT TCGAGCTGGC GGATTTGGAG CAGTTTTACC GCGCCGCCAA AGTGCGCTTT GACGAAGACC CTGCCTTTGC CGACACCGCG CGCGAATACG TTGTGAAGCT GCAAGGCGGC GATGAAACCG TGTTGGCGTT GTGGAAACAG TTTGTCGATA TTTCGCTCTC GCACGCCCAA GCCGTTTACG ACACGCTGGG CTTGAAGCTG CGCCCCGAAG ATGTGGCGGG CGAATCGAAA TACAACGACG ATTTGCAGCC TGTAGCCGAT GATTTGGTTC AAAAAGGCCT GGCGGTTGAG GACGACGGCG CGAAAGTCGT GTTCTTGGAC GAGTTTAAAA ACAAAGAAGG CGAACCCGCC GCATTTATCG TGCAAAAACA AGGCGGCGGC TTCCTTTATG CCTCCACCGA CTTGGCGTGC CTGCGCTACC GCGTCGGCCG TCTCAAAGCC GACCGCCTGC TGTACGTCGT CGACCACCGC CAAGCCCTGC ACTTCGAGCA ACTCTTTACC ACTTCCCGCA AAGCAGGCTA TCTGCCTGAA AATGCAAAAG CCGAGTTTAT CGGCTTCGGC ACCATGATGG GCAAAGACGG CAAACCGTTC AAAACGCGCA GCGGCGACAC CGTAAAACTG GTTGACCTGC TGACCGAAGC CGTCGAGCGC GCCACCGCTT TGGTGAAAGA AAAAAATCCC GAATTGGGCG CGGATGAAGC CGCCAAAATC GGCAAGACCG TCGGCATCGG CGCAGTCAAA TACGCCGATT TAAGCAAAAA CCGCACCAGC GATTATGTGT TCGACTGGGA CGCCATGCTC TCATTTGAAG GCAACACCGC CCCCTACCTG CAATACGCCT ACACCCGCGT GCAAAGCGTG TTCCGCAAAG CCGGAGAATG GGACGCAACC GCACCGACCG TTTTGACCGA ACCACTGGAA AAACAGCTTG CCGCCGAGCT TCTGAAATTT GAAAACGTGC TGCAAAGCGT GGCGGACACC GCGTATCCGC ACTACCTCGC CGCCTACCTT TACCAAGCCG CCACCCTGTT CAGCCGCTTC TACGAAGCTT GCCCGATTTT GAAAGCCGAA GGCGCAAGCC GCAACAGCCG CCTGCAACTG GCAAAACTCA CCGGCAACAC GCTGAAACAA GGCTTGGATT TGCTGGGCAT CGATGTGTTG GACGTAATGT GAGTAAGATA GGATCCGGCT GCTAACAAAG CCCGAAAGGA AGCTGAGTTG GCTGCTGCCA CCGCTGAGCA ATAACTAGCA TAACCCCTTG GGGCCTCTAA ACGGGTCTTG AGGGGTTTTT TGCTGAAAGG AGGAACTATA TCCGGATATC CACAGGACGG GTGTGGTCGC CATGATCGCG TAGTCGATAG TGGCTCCAAG TAGCGAAGCG AGCAGGACTG GGCGGCGGCC AAAGCGGTCG GACAGTGCTC CGAGAACGGG TGCGCATAGA AATTGCATCA ACGCATATAG CGCTAGCAGC ACGCCATAGT GACTGGCGAT GCTGTCGGAA TGGACGATAT CCCGCAAGAG GCCCGGCAGT ACCGGCATAA CCAAGCCTAT GCCTACAGCA TCCAGGGTGA CGGTGCCGAG GATGACGATG AGCGCATTGT TAGATTTCAT ACACGGTGCC TGACTGCGTT AGCAATTTAA CTGTGATAAA CTACCGCATT AAAGCTTATC GATGATAAGC TGTCAAACAT GAGAATTCTT GAAGACGAAA GGGCCTCGTG ATACGCCTAT TTTTATAGGT TAATGTCATG ATAATAATGG TTTCTTAGAC GTCAGGTGGC ACTTTTCGGG GAAATGTGCG CGGAACCCCT ATTTGTTTAT TTTTCTAAAT ACATTCAAAT ATGTATCCGC TCATGAGACA ATAACCCTGA TAAATGCTTC AATAATATTG AAAAAGGAAG AGTATGAGTA TTCAACATTT CCGTGTCGCC CTTATTCCCT TTTTTGCGGC ATTTTGCCTT CCTGTTTTTG CTCACCCAGA AACGCTGGTG AAAGTAAAAG ATGCTGAAGA TCAGTTGGGT GCACGAGTGG GTTACATCGA ACTGGATCTC AACAGCGGTA AGATCCTTGA GAGTTTTCGC CCCGAAGAAC GTTTTCCAAT GATGAGCACT TTTAAAGTTC TGCTATGTGG CGCGGTATTA TCCCGTGTTG ACGCCGGGCA AGAGCAACTC GGTCGCCGCA TACACTATTC TCAGAATGAC TTGGTTGAGT ACTCACCAGT CACAGAAAAG CATCTTACGG ATGGCATGAC AGTAAGAGAA TTATGCAGTG CTGCCATAAC CATGAGTGAT AACACTGCGG CCAACTTACT TCTGACAACG ATCGGAGGAC CGAAGGAGCT AACCGCTTTT TTGCACAACA TGGGGGATCA TGTAACTCGC CTTGATCGTT GGGAACCGGA GCTGAATGAA GCCATACCAA ACGACGAGCG TGACACCACG ATGCCTGCAG CAATGGCAAC AACGTTGCGC AAACTATTAA CTGGCGAACT ACTTACTCTA GCTTCCCGGC AACAATTAAT AGACTGGATG GAGGCGGATA AAGTTGCAGG ACCACTTCTG CGCTCGGCCC TTCCGGCTGG CTGGTTTATT GCTGATAAAT CTGGAGCCGG TGAGCGTGGG TCTCGCGGTA TCATTGCAGC ACTGGGGCCA GATGGTAAGC CCTCCCGTAT CGTAGTTATC TACACGACGG GGAGTCAGGC AACTATGGAT GAACGAAATA GACAGATCGC TGAGATAGGT GCCTCACTGA TTAAGCATTG GTAACTGTCA GACCAAGTTT ACTCATATAT ACTTTAGATT GATTTAAAAC TTCATTTTTA ATTTAAAAGG ATCTAGGTGA AGATCCTTTT TGATAATCTC ATGACCAAAA TCCCTTAACG TGAGTTTTCG TTCCACTGAG CGTCAGACCC CGTAGAAAAG ATCAAAGGAT CTTCTTGAGA TCCTTTTTTT CTGCGCGTAA TCTGCTGCTT GCAAACAAAA AAACCACCGC TACCAGCGGT GGTTTGTTTG CCGGATCAAG AGCTACCAAC TCTTTTTCCG AAGGTAACTG GCTTCAGCAG AGCGCAGATA CCAAATACTG TCCTTCTAGT GTAGCCGTAG TTAGGCCACC ACTTCAAGAA CTCTGTAGCA CCGCCTACAT ACCTCGCTCT GCTAATCCTG TTACCAGTGG CTGCTGCCAG TGGCGATAAG TCGTGTCTTA CCGGGTTGGA CTCAAGACGA TAGTTACCGG ATAAGGCGCA GCGGTCGGGC TGAACGGGGG GTTCGTGCAC ACAGCCCAGC TTGGAGCGAA CGACCTACAC CGAACTGAGA TACCTACAGC GTGAGCTATG AGAAAGCGCC ACGCTTCCCG AAGGGAGAAA GGCGGACAGG TATCCGGTAA GCGGCAGGGT CGGAACAGGA GAGCGCACGA GGGAGCTTCC AGGGGGAAAC GCCTGGTATC TTTATAGTCC TGTCGGGTTT CGCCACCTCT GACTTGAGCG TCGATTTTTG TGATGCTCGT CAGGGGGGCG GAGCCTATGG AAAAACGCCA GCAACGCGGC CTTTTTACGG TTCCTGGCCT TTTGCTGGCC TTTTGCTCAC ATGTTCTTTC CTGCGTTATC CCCTGATTCT GTGGATAACC GTATTACCGC CTTTGAGTGA GCTGATACCG CTCGCCGCAG CCGAACGACC GAGCGCAGCG AGTCAGTGAG CGAGGAAGCG GAAGAGCGCC TGATGCGGTA TTTTCTCCTT ACGCATCTGT GCGGTATTTC ACACCGCATA TATGGTGCAC TCTCAGTACA ATCTGCTCTG ATGCCGCATA GTTAAGCCAG TATACACTCC GCTATCGCTA CGTGACTGGG TCATGGCTGC GCCCCGACAC CCGCCAACAC CCGCTGACGC GCCCTGACGG GCTTGTCTGC TCCCGGCATC CGCTTACAGA CAAGCTGTGA CCGTCTCCGG GAGCTGCATG TGTCAGAGGT TTTCACCGTC ATCACCGAAA CGCGCGAGGC AGCTGCGGTA AAGCTCATCA GCGTGGTCGT GAAGCGATTC ACAGATGTCT GCCTGTTCAT CCGCGTCCAG CTCGTTGAGT TTCTCCAGAA GCGTTAATGT CTGGCTTCTG ATAAAGCGGG CCATGTTAAG GGCGGTTTTT TCCTGTTTGG TCACTGATGC CTCCGTGTAA GGGGGATTTC TGTTCATGGG GGTAATGATA CCGATGAAAC GAGAGAGGAT GCTCACGATA CGGGTTACTG ATGATGAACA TGCCCGGTTA CTGGAACGTT GTGAGGGTAA ACAACTGGCG GTATGGATGC GGCGGGACCA GAGAAAAATC ACTCAGGGTC AATGCCAGCG CTTCGTTAAT ACAGATGTAG GTGTTCCACA GGGTAGCCAG CAGCATCCTG CGATGCAGAT CCGGAACATA ATGGTGCAGG GCGCTGACTT CCGCGTTTCC AGACTTTACG AAACACGGAA ACCGAAGACC ATTCATGTTG TTGCTCAGGT CGCAGACGTT TTGCAGCAGC AGTCGCTTCA CGTTCGCTCG CGTATCGGTG ATTCATTCTG CTAACCAGTA AGGCAACCCC GCCAGCCTAG CCGGGTCCTC AACGACAGGA GCACGATCAT GCGCACCCGT GGCCAGGACC CAACGCTGCC CGAGATGCGC CGCGTGCGGC TGCTGGAGAT GGCGGACGCG ATGGATATGT TCTGCCAAGG GTTGGTTTGC GCATTCACAG TTCTCCGCAA GAATTGATTG GCTCCAATTC TTGGAGTGGT GAATCCGTTA GCGAGGTGCC GCCGGCTTCC ATTCAGGTCG AGGTGGCCCG GCTCCATGCA CCGCGACGCA ACGCGGGGAG GCAGACAAGG TATAGGGCGG CGCCTACAAT CCATGCCAAC CCGTTCCATG TGCTCGCCGA GGCGGCATAA ATCGCCGTGA CGATCAGCGG TCCAGTGATC GAAGTTAGGC TGGTAAGAGC CGCGAGCGAT CCTTGAAGCT GTCCCTGATG GTCGTCATCT ACCTGCCTGG ACAGCATGGC CTGCAACGCG GGCATCCCGA TGCCGCCGGA AGCGAGAAGA ATCATAATGG GGAAGGCCAT CCAGCCTCGC GTCGCGAACG CCAGCAAGAC GTAGCCCAGC GCGTCGGCCG CCATGCCGGC GATAATGGCC TGCTTCTCGC CGAAACGTTT GGTGGCGGGA CCAGTGACGA AGGCTTGAGC GAGGGCGTGC AAGATTCCGA ATACCGCAAG CGACAGGCCG ATCATCGTCG CGCTCCAGCG AAAGCGGTCC TCGCCGAAAA TGACCCAGAG CGCTGCCGGC ACCTGTCCTA CGAGTTGCAT GATAAAGAAG ACAGTCATAA GTGCGGCGAC GATAGTCATG CCCCGCGCCC ACCGGAAGGA GCTGACTGGG TTGAAGGCTC TCAAGGGCAT CGGTCGACGC TCTCCCTTAT GCGACTCCTG CATTAGGAAG CAGCCCAGTA GTAGGTTGAG GCCGTTGAGC ACCGCCGCCG CAAGGAATGG TGCATGCAAG GAGATGGCGC CCAACAGTCC CCCGGCCACG GGGCCTGCCA CCATACCCAC GCCGAAACAA GCGCTCATGA GCCCGAAGTG GCGAGCCCGA TCTTCCCCAT CGGTGATGTC GGCGATATAG GCGCCAGCAA CCGCACCTGT GGCGCCGGTG ATGCCGGCCA CGATGCGTCC GGCGTAGAGG ATCGAGATCT CGATCCCGCG AAAT