MumuA.20194.a
Ig heavy chain; IgG
| CENTER ID: | MumuA.20194.a |
| ORGANISM: | Mus musculus |
| ASSOCIATED DISEASE: | |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | True |
| NIH RISK GROUP: | unclassified |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
unclassified |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Structures
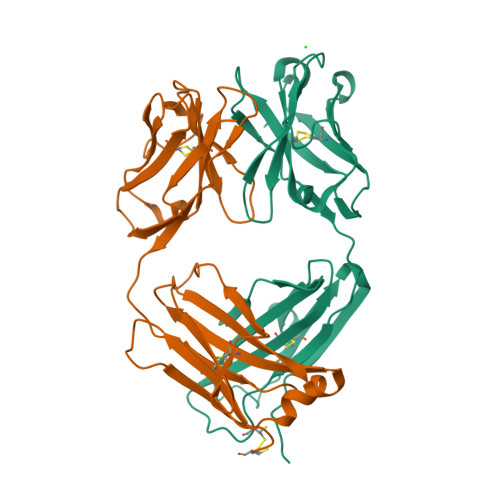
6U1T
DEPOSITED: 8/16/2019
DETERMINATION: XRay
CLONE: MumuA.20194.a.K3.GE43562
PROTEIN: MumuA.20194.a.K3.PE00011
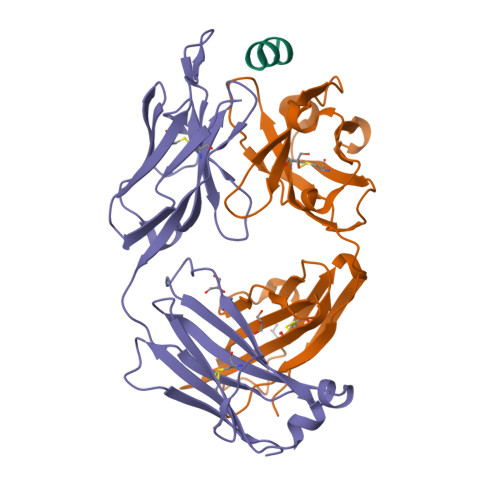
7M51
DEPOSITED: 3/22/2021
DETERMINATION: XRay
CLONE: MumuA.20194.a.K11.GE44372
PROTEIN: MumuA.20194.a.K11.PE00028
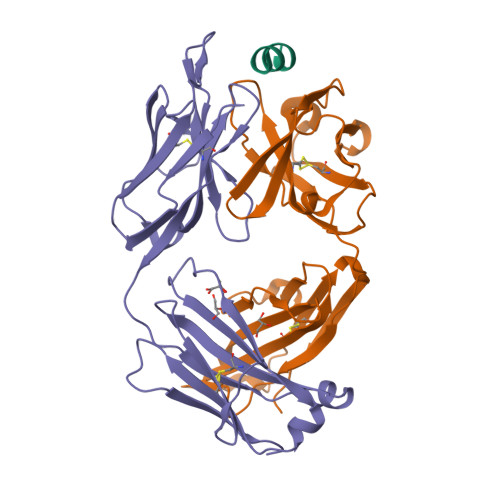
7M52
DEPOSITED: 3/22/2021
DETERMINATION: XRay
CLONE: MumuA.20194.a.K11.GE44372
PROTEIN: MumuA.20194.a.K11.PE00028
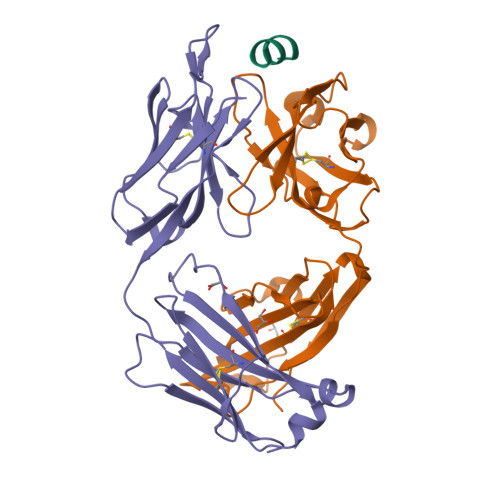
7M53
DEPOSITED: 3/22/2021
DETERMINATION: XRay
CLONE: MumuA.20194.a.K11.GE44372
PROTEIN: MumuA.20194.a.K11.PE00028
7M55
DEPOSITED: 3/22/2021
DETERMINATION: XRay
CLONE: MumuA.20194.a.K11.GE44372
PROTEIN: MumuA.20194.a.K11.PE00028
Publications by SSGCID
An antibody against the F glycoprotein inhibits Nipah and Hendra virus infections.
Snijder J, Veesler D, Park YJ, Dang HV, Chan YP, Vu B, Yan L, Feng YR, Rockx B, Giesbert T, Mire CE, Broder CC
Nat. Struct. Mol. Biol. - 2019
volume 26, issue 30 September 2019, pages 980-987
PMID: 31570878; PMCID: PMC6858553
Structural basis for broad coronavirus neutralization
Tortorici MA, Walls AC, McGuire AT, Bosch BJ, Veesler D, Xiong X, Park YJ, de van der Schueren W, King NP, Sauer MM, Bowen J, Acton O, Homad LJ, Wang C, Quispe J, Hoffstrom BG
Nat. Struct. Mol. Biol. - 2021
volume 82, issue 6, pages 478-486
PMID: 33981021
External Resources
| RESOURCE | REFERENCE ID |
|---|---|
| UniProt: | I6L985 |
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MKLWLNWIFL VTLLNGIQCE VNLVESGGGL VQPGGSLRLS CAASGFTFTD YYMSWVRQPP GKALEWLGFI RNKANGYTTE YSASVKGRFT ISRDNSQSIL YLQMNALRAE DSATYYCARD RRSSYYYSGT SFAYWGQGTL VTVSAAKTTP PSVYPLAPGS AAQTNSMVTL GCLVKGYFPE PVTVTWNSGS LSSGVHTFPA VLQSDLYTLS SSVTVPSSTW PSQTVTCNVA HPASSTKVDK KIVPRDCGCK PCICTVPEVS SVFIFPPKPK DVLTITLTPK VTCVVVDISK DDPEVQFSWF VDDVEVHTAQ TKPREEQFNS TFRSVSELPI MHQDWLNGKE FKCRVNSAAF PAPIEKTISK TKGRPKAPQV YTIPPPKEQM AKDKVSLTCM ITDFFPEDIT VEWQWNGQPA ENYKNTQPIM DTDGSYFVYS KLNVQKSNWE AGNTFTCSVL HEGLHNHHTE KSLSHSPGK
NT Sequence
ATGAAGTTGT GGCTGAACTG GATTTTCCTT GTAACACTTT TAAATGGTAT CCAGTGTGAG GTGAATCTGG TGGAGTCTGG AGGAGGCTTG GTACAGCCTG GGGGTTCTCT GCGTCTCTCC TGTGCAGCTT CTGGATTCAC CTTTACTGAT TACTACATGA GCTGGGTCCG CCAGCCTCCA GGGAAGGCAC TTGAGTGGTT GGGTTTTATT AGAAACAAAG CTAATGGTTA CACAACAGAG TACAGTGCAT CTGTGAAGGG TCGGTTCACC ATCTCCAGAG ATAATTCCCA AAGCATCCTC TATCTTCAAA TGAATGCCCT GAGAGCTGAG GACAGTGCCA CTTATTACTG TGCAAGAGAT AGGAGGAGTT CTTATTACTA CAGTGGTACC TCCTTTGCTT ACTGGGGCCA AGGGACTCTG GTCACTGTCT CTGCAGCCAA AACGACACCC CCATCTGTCT ATCCACTGGC CCCTGGATCT GCTGCCCAAA CTAACTCCAT GGTGACCCTG GGATGCCTGG TCAAGGGCTA TTTCCCTGAG CCAGTGACAG TGACCTGGAA CTCTGGATCC CTGTCCAGCG GTGTGCACAC CTTCCCAGCT GTCCTGCAGT CTGACCTCTA CACTCTGAGC AGCTCAGTGA CTGTCCCCTC CAGCACCTGG CCCAGCCAGA CCGTCACCTG CAACGTTGCC CACCCGGCCA GCAGCACCAA GGTGGACAAG AAAATTGTGC CCAGGGATTG TGGTTGTAAG CCTTGCATAT GTACAGTCCC AGAAGTATCA TCTGTCTTCA TCTTCCCCCC AAAGCCCAAG GATGTGCTCA CCATTACTCT GACTCCTAAG GTCACGTGTG TTGTGGTAGA CATCAGCAAG GATGATCCCG AGGTCCAGTT CAGCTGGTTT GTAGATGATG TGGAGGTGCA CACAGCTCAG ACAAAACCCC GGGAGGAGCA GTTCAACAGC ACTTTCCGTT CAGTCAGTGA ACTTCCCATC ATGCACCAGG ACTGGCTCAA TGGCAAGGAG TTCAAATGCA GGGTCAACAG TGCAGCTTTC CCTGCCCCCA TCGAGAAAAC CATCTCCAAA ACCAAAGGCA GACCGAAGGC TCCACAGGTG TACACCATTC CACCTCCCAA GGAGCAGATG GCCAAGGATA AAGTCAGTCT GACCTGCATG ATAACAGACT TCTTCCCTGA AGACATTACT GTGGAGTGGC AGTGGAATGG GCAGCCAGCG GAGAACTACA AGAACACTCA GCCCATCATG GACACAGATG GCTCTTACTT CGTCTACAGC AAGCTCAATG TGCAGAAGAG CAACTGGGAG GCAGGAAATA CTTTCACCTG CTCTGTGTTA CATGAGGGCC TGCACAACCA CCATACTGAG AAGAGCCTCT CCCACTCTCC TGGTAAA