LemaA.01212.a
Cytosolic malate dehydrogenase, putative
| CENTER ID: | LemaA.01212.a |
| ORGANISM: | Leishmania major Friedlin |
| ASSOCIATED DISEASE: | Cutaneous leishmaniasis |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | True |
| NIH RISK GROUP: | 2 |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
unclassified |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Clones*
| CENTER REFERENCE ID |
DOMAIN/REGION DESCRIPTION |
INFO | AA START |
AA STOP |
ORDER MATERIAL |
|---|---|---|---|---|---|
| LemaA.01212.a.A1.GE34358 | full length | 1 | 324 |
* SSGCID clones represent un-induced expression constructs which have been verified by sequencing from vector primers. Clones may contain a tag, such as N-term 6xHis. Get sequence information
using the button in the "info" column.
Proteins
| CENTER REFERENCE ID |
DOMAIN/REGION DESCRIPTION |
INFO | AA START |
AA STOP |
ORDER MATERIAL |
|---|---|---|---|---|---|
| LemaA.01212.a.A1.PS01468 | full length | 1 | 324 |
Structures

4H7P
DEPOSITED: 9/20/2012
DETERMINATION: XRay
CLONE: LemaA.01212.a.A1.GE34358
PROTEIN: LemaA.01212.a.A1.PS01468
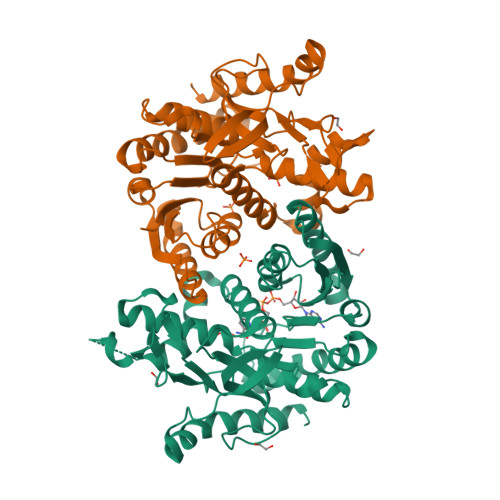
4I1I
DEPOSITED: 11/21/2012
DETERMINATION: XRay
CLONE: LemaA.01212.a.A1.GE34358
PROTEIN: LemaA.01212.a.A1.PS01468
External Resources
| RESOURCE | REFERENCE ID |
|---|---|
| EuPathDB: | TritrypDB:LmjF28.2860 |
| RefSeq: | XP_001684572.1 |
| UniProt: | Q4Q7X6 |
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MSAVKVAVTG AAGQIGYALV PLIARGALLG PTTPVELRLL DIEPALKALA GVEAELEDCA FPLLDKVVVT ADPRVAFDGV AIAIMCGAFP RKAGMERKDL LEMNARIFKE QGEAIAAVAA SDCRVVVVGN PANTNALILL KSAQGKLNPR HVTAMTRLDH NRALSLLARK AGVPVSQVRN VIIWGNHSST QVPDTDSAVI GTTPAREAIK DDALDDDFVQ VVRGRGAEII QLRGLSSAMS AAKAAVDHVH DWIHGTPEGV YVSMGVYSDE NPYGVPSGLI FSFPCTCHAG EWTVVSGKLN GDLGKQRLAS TIAELQEERA QAGL
NT Sequence
atgtccgctg tgaaggtggc cgtgacgggt gcggctggtc agatcgggta tgcattggta ccgctgatcg cgcgcggcgc cctcctcggg cccaccacgc ctgtggagct ccgcctgctg gatatcgagc ccgctctgaa ggcgcttgcc ggcgtcgaag cggagctgga agactgcgcc ttccctctcc tggacaaggt cgtcgtcacg gcagacccgc gcgttgcctt cgacggggtc gccattgcca tcatgtgcgg tgccttcccg cgcaaggcag ggatggagcg caaggacctc ctcgagatga acgcgcgcat cttcaaggag cagggtgagg ccatcgctgc tgtggccgcg tcagactgcc gcgtggtggt tgtcggcaat ccggccaaca caaacgctct catcctcctc aagtcagctc aggggaagtt gaacccccgt catgtgaccg ccatgacccg cctcgatcac aaccgtgcct tgtctcttct ggctcgcaag gccggtgtgc cggtgtcgca ggtgcgcaac gtgatcatct ggggcaacca tagctctaca caggtccctg acactgacag cgctgtgatc ggcaccactc cggcccgcga agcgatcaag gacgatgcac tcgatgacga ctttgtgcag gtggtgcgcg ggcgcggcgc cgaaatcatc caactacgtg gtctttcctc agccatgtcc gccgccaagg ccgccgtaga ccacgtacat gactggatac atggcacacc ggagggcgtg tacgtttcga tgggcgtgta ctcggatgaa aacccgtacg gcgtgccgag cggcctcatc ttctcctttc cgtgcacgtg ccacgccggc gagtggactg ttgtctcggg caagctgaat ggggacctcg ggaagcagcg tctcgccagc acgatcgccg agctgcagga ggagagggca caggcagggc tatga
Details for LemaA.01212.a.A1.GE34358
| HARVESTED ON: | 1/10/2012 |
| SEQUENCED ON: | 1/13/2012 |
| EXPECTED MW: | 36kDa |
| OBSERVED MW: | 36kDa |
| ANTIBIOTIC MARKER: | ampicillin |
| COUNT OF EXPRESSION COLONIES: | Too many to count (100+) |
| TOTAL EXPRESSION LEVEL: | Moderate Expression |
| SOLUBLE EXPRESSION LEVEL | Moderate Expression |
| EXPRESSION HOST: | data unavailable |
| SEQUENCING RESULT: | pass with incomplete coverage |
| PERCENT IDENTITY: | 100 |
| PERCENT COVERAGE: | 93 |
Validated AA Sequence
MSAVKVAVTG AAGQIGYALV PLIARGALLG PTTPVELRLL DIEPALKALA GVEAELEDCA FPLLDKVVVT ADPRVAFDGV AIAIMCGAFP RKAGMERKDL LEMNARIFKE QGEAIAAVAA SDCRVVVVGN PANTNALILL KSAQGKLNPR HVTAMTRLDH NRALSLLARK AGVPVSQVRN VIIWGNHSST QVPDTDSAVI GTTPAREAIK DDALDDDFVQ VVRGRGAEII QLRGLSSAMS AAKAAVDHVH DWIHGTPEGV YVSMGVYSDE NPYGVPSGLI FSFPCTCHAG EWTVVSGKLN GDLGKQRLAS TIAELQEERA QAG
Validated NT Sequence
tagccctgcc tgtgccctct cctcctgcag ctcggcgatc gtgctggcga gacgctgctt cccgaggtcc ccattcagct tgcccgagac aacagtccac tcgccggcgt ggcacgtgca cggaaaggag aagatgaggc cgctcggcac gccgtacggg ttttcatccg agtacacgcc catcgaaacg tacacgccct ccggtgtgcc atgtatccag tcatgtacgt ggtctacggc ggccttggcg gcggacatgg ctgaggaaag accacgtagt tggatgattt cggcgccgcg cccgcgcacc acctgcacaa agtcgtcatc gagtgcatcg tccttgatcg cttcgcgggc cggagtggtg ccgatcacag cgctgtcagt gtcagggacc tgtgtagagc tatggttgcc ccagatgatc acgttgcgca cctgcgacac cggcacaccg gccttgcgag ccagaagaga caaggcacgg ttgtgatcga ggcgggtcat ggcggtcaca tgacgggggt tcaacttccc ctgagctgac ttgaggagga tgagagcgtt tgtgttggcc ggattgccga caaccaccac gcggcagtct gacgcggcca cagcagcgat ggcctcaccc tgctccttga agatgcgcgc gttcatctcg aggaggtcct tgcgctccat ccctgccttg cgcgggaagg caccgcacat gatggcaatg gcgaccccgt cgaaggcaac gcgcgggtct gccgtgacga cgaccttgtc caggagaggg aaggcgcagt cttccagctc cgcttcgacg ccggcaagcg ccttcagagc gggctcgata tccagcaggc ggagctccac aggcgtggtg ggcccgagga gggcgccgcg cgcgatcagc ggtaccaatg catacccgat ctgaccagcc gcacccgtca cggccacctt cacagcggac atcgaaccag gaccctgggt ctgagcttcc agggt
Expected Protein Sequence
MAHHHHHHMG TLEAQTQGPG SMSAVKVAVT GAAGQIGYAL VPLIARGALL GPTTPVELRL LDIEPALKAL AGVEAELEDC AFPLLDKVVV TADPRVAFDG VAIAIMCGAF PRKAGMERKD LLEMNARIFK EQGEAIAAVA ASDCRVVVVG NPANTNALIL LKSAQGKLNP RHVTAMTRLD HNRALSLLAR KAGVPVSQVR NVIIWGNHSS TQVPDTDSAV IGTTPAREAI KDDALDDDFV QVVRGRGAEI IQLRGLSSAM SAAKAAVDHV HDWIHGTPEG VYVSMGVYSD ENPYGVPSGL IFSFPCTCHA GEWTVVSGKL NGDLGKQRLA STIAELQEER AQAGL
Full NT Sequence (Expression Vector + Insert)
ttcttgaaga cgaaagggcc tcgtgatacg cctattttta taggttaatg tcatgataat aatggtttct tagacgtcag gtggcacttt tcggggaaat gtgcgcggaa cccctatttg tttatttttc taaatacatt caaatatgta tccgctcatg agacaataac cctgataaat gcttcaataa tattgaaaaa ggaagagtat gagtattcaa catttccgtg tcgcccttat tccctttttt gcggcatttt gccttcctgt ttttgctcac ccagaaacgc tggtgaaagt aaaagatgct gaagatcagt tgggtgcacg agtgggttac atcgaactgg atctcaacag cggtaagatc cttgagagtt ttcgccccga agaacgtttt ccaatgatga gcacttttaa agttctgcta tgtggcgcgg tattatcccg tgttgacgcc gggcaagagc aactcggtcg ccgcatacac tattctcaga atgacttggt tgagtactca ccagtcacag aaaagcatct tacggatggc atgacagtaa gagaattatg cagtgctgcc ataaccatga gtgataacac tgcggccaac ttacttctga caacgatcgg aggaccgaag gagctaaccg cttttttgca caacatgggg gatcatgtaa ctcgccttga tcgttgggaa ccggagctga atgaagccat accaaacgac gagcgtgaca ccacgatgcc tgcagcaatg gcaacaacgt tgcgcaaact attaactggc gaactactta ctctagcttc ccggcaacaa ttaatagact ggatggaggc ggataaagtt gcaggaccac ttctgcgctc ggcccttccg gctggctggt ttattgctga taaatctgga gccggtgagc gtgggtctcg cggtatcatt gcagcactgg ggccagatgg taagccctcc cgtatcgtag ttatctacac gacggggagt caggcaacta tggatgaacg aaatagacag atcgctgaga taggtgcctc actgattaag cattggtaac tgtcagacca agtttactca tatatacttt agattgattt aaaacttcat ttttaattta aaaggatcta ggtgaagatc ctttttgata atctcatgac caaaatccct taacgtgagt tttcgttcca ctgagcgtca gaccccgtag aaaagatcaa aggatcttct tgagatcctt tttttctgcg cgtaatctgc tgcttgcaaa caaaaaaacc accgctacca gcggtggttt gtttgccgga tcaagagcta ccaactcttt ttccgaaggt aactggcttc agcagagcgc agataccaaa tactgtcctt ctagtgtagc cgtagttagg ccaccacttc aagaactctg tagcaccgcc tacatacctc gctctgctaa tcctgttacc agtggctgct gccagtggcg ataagtcgtg tcttaccggg ttggactcaa gacgatagtt accggataag gcgcagcggt cgggctgaac ggggggttcg tgcacacagc ccagcttgga gcgaacgacc tacaccgaac tgagatacct acagcgtgag ctatgagaaa gcgccacgct tcccgaaggg agaaaggcgg acaggtatcc ggtaagcggc agggtcggaa caggagagcg cacgagggag cttccagggg gaaacgcctg gtatctttat agtcctgtcg ggtttcgcca cctctgactt gagcgtcgat ttttgtgatg ctcgtcaggg gggcggagcc tatggaaaaa cgccagcaac gcggcctttt tacggttcct ggccttttgc tggccttttg ctcacatgtt ctttcctgcg ttatcccctg attctgtgga taaccgtatt accgcctttg agtgagctga taccgctcgc cgcagccgaa cgaccgagcg cagcgagtca gtgagcgagg aagcggaaga gcgcctgatg cggtattttc tccttacgca tctgtgcggt atttcacacc gcatatatgg tgcactctca gtacaatctg ctctgatgcc gcatagttaa gccagtatac actccgctat cgctacgtga ctgggtcatg gctgcgcccc gacacccgcc aacacccgct gacgcgccct gacgggcttg tctgctcccg gcatccgctt acagacaagc tgtgaccgtc tccgggagct gcatgtgtca gaggttttca ccgtcatcac cgaaacgcgc gaggcagctg cggtaaagct catcagcgtg gtcgtgaagc gattcacaga tgtctgcctg ttcatccgcg tccagctcgt tgagtttctc cagaagcgtt aatgtctggc ttctgataaa gcgggccatg ttaagggcgg ttttttcctg tttggtcact gatgcctccg tgtaaggggg atttctgttc atgggggtaa tgataccgat gaaacgagag aggatgctca cgatacgggt tactgatgat gaacatgccc ggttactgga acgttgtgag ggtaaacaac tggcggtatg gatgcggcgg gaccagagaa aaatcactca gggtcaatgc cagcgcttcg ttaatacaga tgtaggtgtt ccacagggta gccagcagca tcctgcgatg cagatccgga acataatggt gcagggcgct gacttccgcg tttccagact ttacgaaaca cggaaaccga agaccattca tgttgttgct caggtcgcag acgttttgca gcagcagtcg cttcacgttc gctcgcgtat cggtgattca ttctgctaac cagtaaggca accccgccag cctagccggg tcctcaacga caggagcacg atcatgcgca cccgtggcca ggacccaacg ctgcccgaga tgcgccgcgt gcggctgctg gagatggcgg acgcgatgga tatgttctgc caagggttgg tttgcgcatt cacagttctc cgcaagaatt gattggctcc aattcttgga gtggtgaatc cgttagcgag gtgccgccgg cttccattca ggtcgaggtg gcccggctcc atgcaccgcg acgcaacgcg gggaggcaga caaggtatag ggcggcgcct acaatccatg ccaacccgtt ccatgtgctc gccgaggcgg cataaatcgc cgtgacgatc agcggtccag tgatcgaagt taggctggta agagccgcga gcgatccttg aagctgtccc tgatggtcgt catctacctg cctggacagc atggcctgca acgcgggcat cccgatgccg ccggaagcga gaagaatcat aatggggaag gccatccagc ctcgcgtcgt gaacgccagc aagacgtagc ccagcgcgtc ggccgtaaca acaccattta aatggagtgg ttacaaatgg agtggttaat taacaacacc atttgtcgac gctctccctt atgcgactcc tgcattagga agcagcccag tagtaggttg aggccgttga gcaccgccgc cgcaaggaat ggtgcatgca aggagatggc gcccaacagt cccccggcca cggggcctgc caccataccc acgccgaaac aagcgctcat gagcccgaag tggcgagccc gatcttcccc atcggtgatg tcggcgatat aggcgccagc aaccgcacct gtggcgccgg tgatgccggc cacgatgcgt ccggcgtaga ggatcgagat ctcgatcccg cgaaattaat acgactcact atagggagac cacaacggtt tccctctaga aataattttg tttaacttta agaaggagat ataccatggc tcatcaccat caccatcata tgggtaccct ggaagctcag acccagggtc ctggttcgat gtccgctgtg aaggtggccg tgacgggtgc ggctggtcag atcgggtatg cattggtacc gctgatcgcg cgcggcgccc tcctcgggcc caccacgcct gtggagctcc gcctgctgga tatcgagccc gctctgaagg cgcttgccgg cgtcgaagcg gagctggaag actgcgcctt ccctctcctg gacaaggtcg tcgtcacggc agacccgcgc gttgccttcg acggggtcgc cattgccatc atgtgcggtg ccttcccgcg caaggcaggg atggagcgca aggacctcct cgagatgaac gcgcgcatct tcaaggagca gggtgaggcc atcgctgctg tggccgcgtc agactgccgc gtggtggttg tcggcaatcc ggccaacaca aacgctctca tcctcctcaa gtcagctcag gggaagttga acccccgtca tgtgaccgcc atgacccgcc tcgatcacaa ccgtgccttg tctcttctgg ctcgcaaggc cggtgtgccg gtgtcgcagg tgcgcaacgt gatcatctgg ggcaaccata gctctacaca ggtccctgac actgacagcg ctgtgatcgg caccactccg gcccgcgaag cgatcaagga cgatgcactc gatgacgact ttgtgcaggt ggtgcgcggg cgcggcgccg aaatcatcca actacgtggt ctttcctcag ccatgtccgc cgccaaggcc gccgtagacc acgtacatga ctggatacat ggcacaccgg agggcgtgta cgtttcgatg ggcgtgtact cggatgaaaa cccgtacggc gtgccgagcg gcctcatctt ctcctttccg tgcacgtgcc acgccggcga gtggactgtt gtctcgggca agctgaatgg ggacctcggg aagcagcgtc tcgccagcac gatcgccgag ctgcaggagg agagggcaca ggcagggcta taaacagcac gaacaagttc tgcagccaag cttctcgagg atccggctgc taacaaagcc cgaaaggaag ctgagttggc tgctgccacc gctgagcaat aactagcata accccttggg gcctctaaac gggtcttgag gggttttttg ctgaaaggag gaactatatc cggatatcca caggacgggt gtggtcgcca tgatcgcgta gtcgatagtg gctccaagta gcgaagcgag caggactggg cggcggccaa agcggtcgga cagtgctccg agaacgggtg cgcatagaaa ttgcatcaac gcatatagcg ctagcagcac gccatagtga ctggcgatgc tgtcggaatg gacgatatcc cgcaagaggc ccggcagtac cggcataacc aagcctatgc ctacagcatc cagggtgacg gtgccgagga tgacgatgag cgcattgtta gatttcatac acggtgcctg actgcgttag caatttaact gtgataaact accgcattaa agcttatcga tgataagctg tcaaacatga gaa
Details for LemaA.01212.a.A1.PS01468
| PURIFICATION DATe: | 4/20/2012 |
| CONCENTRATION: | 130.26mg/ml |
| OBSERVED MW: | 36kDa |
| EXPRESSION LEVEL: | Low Expression |
| PROTEIN PURIFICATION BUFFER: | 20 mM HEPES, pH 7.0, 300 mM NaCl, 5% glycerol and 1 mM TCEP |
| EXPRESSION HOST: | data unavailable |
| VIAL COUNT (approx.): | 4 |
| VIAL VOLUME: | 110µl |
| PERCENT IDENTITY: | 100 |
| PERCENT COVERAGE: | 93 |
Protocol Notes
notes unavailable
Validated AA Sequence
MSAVKVAVTG AAGQIGYALV PLIARGALLG PTTPVELRLL DIEPALKALA GVEAELEDCA FPLLDKVVVT ADPRVAFDGV AIAIMCGAFP RKAGMERKDL LEMNARIFKE QGEAIAAVAA SDCRVVVVGN PANTNALILL KSAQGKLNPR HVTAMTRLDH NRALSLLARK AGVPVSQVRN VIIWGNHSST QVPDTDSAVI GTTPAREAIK DDALDDDFVQ VVRGRGAEII QLRGLSSAMS AAKAAVDHVH DWIHGTPEGV YVSMGVYSDE NPYGVPSGLI FSFPCTCHAG EWTVVSGKLN GDLGKQRLAS TIAELQEERA QAG
Validated NT Sequence
tagccctgcc tgtgccctct cctcctgcag ctcggcgatc gtgctggcga gacgctgctt cccgaggtcc ccattcagct tgcccgagac aacagtccac tcgccggcgt ggcacgtgca cggaaaggag aagatgaggc cgctcggcac gccgtacggg ttttcatccg agtacacgcc catcgaaacg tacacgccct ccggtgtgcc atgtatccag tcatgtacgt ggtctacggc ggccttggcg gcggacatgg ctgaggaaag accacgtagt tggatgattt cggcgccgcg cccgcgcacc acctgcacaa agtcgtcatc gagtgcatcg tccttgatcg cttcgcgggc cggagtggtg ccgatcacag cgctgtcagt gtcagggacc tgtgtagagc tatggttgcc ccagatgatc acgttgcgca cctgcgacac cggcacaccg gccttgcgag ccagaagaga caaggcacgg ttgtgatcga ggcgggtcat ggcggtcaca tgacgggggt tcaacttccc ctgagctgac ttgaggagga tgagagcgtt tgtgttggcc ggattgccga caaccaccac gcggcagtct gacgcggcca cagcagcgat ggcctcaccc tgctccttga agatgcgcgc gttcatctcg aggaggtcct tgcgctccat ccctgccttg cgcgggaagg caccgcacat gatggcaatg gcgaccccgt cgaaggcaac gcgcgggtct gccgtgacga cgaccttgtc caggagaggg aaggcgcagt cttccagctc cgcttcgacg ccggcaagcg ccttcagagc gggctcgata tccagcaggc ggagctccac aggcgtggtg ggcccgagga gggcgccgcg cgcgatcagc ggtaccaatg catacccgat ctgaccagcc gcacccgtca cggccacctt cacagcggac atcgaaccag gaccctgggt ctgagcttcc agggt
Expressed Protein Sequence
MAHHHHHHMG TLEAQTQGPG SMSAVKVAVT GAAGQIGYAL VPLIARGALL GPTTPVELRL LDIEPALKAL AGVEAELEDC AFPLLDKVVV TADPRVAFDG VAIAIMCGAF PRKAGMERKD LLEMNARIFK EQGEAIAAVA ASDCRVVVVG NPANTNALIL LKSAQGKLNP RHVTAMTRLD HNRALSLLAR KAGVPVSQVR NVIIWGNHSS TQVPDTDSAV IGTTPAREAI KDDALDDDFV QVVRGRGAEI IQLRGLSSAM SAAKAAVDHV HDWIHGTPEG VYVSMGVYSD ENPYGVPSGL IFSFPCTCHA GEWTVVSGKL NGDLGKQRLA STIAELQEER AQAGL
Full NT Sequence (Expression Vector + Insert)
TTCTTGAAGA CGAAAGGGCC TCGTGATACG CCTATTTTTA TAGGTTAATG TCATGATAAT AATGGTTTCT TAGACGTCAG GTGGCACTTT TCGGGGAAAT GTGCGCGGAA CCCCTATTTG TTTATTTTTC TAAATACATT CAAATATGTA TCCGCTCATG AGACAATAAC CCTGATAAAT GCTTCAATAA TATTGAAAAA GGAAGAGTAT GAGTATTCAA CATTTCCGTG TCGCCCTTAT TCCCTTTTTT GCGGCATTTT GCCTTCCTGT TTTTGCTCAC CCAGAAACGC TGGTGAAAGT AAAAGATGCT GAAGATCAGT TGGGTGCACG AGTGGGTTAC ATCGAACTGG ATCTCAACAG CGGTAAGATC CTTGAGAGTT TTCGCCCCGA AGAACGTTTT CCAATGATGA GCACTTTTAA AGTTCTGCTA TGTGGCGCGG TATTATCCCG TGTTGACGCC GGGCAAGAGC AACTCGGTCG CCGCATACAC TATTCTCAGA ATGACTTGGT TGAGTACTCA CCAGTCACAG AAAAGCATCT TACGGATGGC ATGACAGTAA GAGAATTATG CAGTGCTGCC ATAACCATGA GTGATAACAC TGCGGCCAAC TTACTTCTGA CAACGATCGG AGGACCGAAG GAGCTAACCG CTTTTTTGCA CAACATGGGG GATCATGTAA CTCGCCTTGA TCGTTGGGAA CCGGAGCTGA ATGAAGCCAT ACCAAACGAC GAGCGTGACA CCACGATGCC TGCAGCAATG GCAACAACGT TGCGCAAACT ATTAACTGGC GAACTACTTA CTCTAGCTTC CCGGCAACAA TTAATAGACT GGATGGAGGC GGATAAAGTT GCAGGACCAC TTCTGCGCTC GGCCCTTCCG GCTGGCTGGT TTATTGCTGA TAAATCTGGA GCCGGTGAGC GTGGGTCTCG CGGTATCATT GCAGCACTGG GGCCAGATGG TAAGCCCTCC CGTATCGTAG TTATCTACAC GACGGGGAGT CAGGCAACTA TGGATGAACG AAATAGACAG ATCGCTGAGA TAGGTGCCTC ACTGATTAAG CATTGGTAAC TGTCAGACCA AGTTTACTCA TATATACTTT AGATTGATTT AAAACTTCAT TTTTAATTTA AAAGGATCTA GGTGAAGATC CTTTTTGATA ATCTCATGAC CAAAATCCCT TAACGTGAGT TTTCGTTCCA CTGAGCGTCA GACCCCGTAG AAAAGATCAA AGGATCTTCT TGAGATCCTT TTTTTCTGCG CGTAATCTGC TGCTTGCAAA CAAAAAAACC ACCGCTACCA GCGGTGGTTT GTTTGCCGGA TCAAGAGCTA CCAACTCTTT TTCCGAAGGT AACTGGCTTC AGCAGAGCGC AGATACCAAA TACTGTCCTT CTAGTGTAGC CGTAGTTAGG CCACCACTTC AAGAACTCTG TAGCACCGCC TACATACCTC GCTCTGCTAA TCCTGTTACC AGTGGCTGCT GCCAGTGGCG ATAAGTCGTG TCTTACCGGG TTGGACTCAA GACGATAGTT ACCGGATAAG GCGCAGCGGT CGGGCTGAAC GGGGGGTTCG TGCACACAGC CCAGCTTGGA GCGAACGACC TACACCGAAC TGAGATACCT ACAGCGTGAG CTATGAGAAA GCGCCACGCT TCCCGAAGGG AGAAAGGCGG ACAGGTATCC GGTAAGCGGC AGGGTCGGAA CAGGAGAGCG CACGAGGGAG CTTCCAGGGG GAAACGCCTG GTATCTTTAT AGTCCTGTCG GGTTTCGCCA CCTCTGACTT GAGCGTCGAT TTTTGTGATG CTCGTCAGGG GGGCGGAGCC TATGGAAAAA CGCCAGCAAC GCGGCCTTTT TACGGTTCCT GGCCTTTTGC TGGCCTTTTG CTCACATGTT CTTTCCTGCG TTATCCCCTG ATTCTGTGGA TAACCGTATT ACCGCCTTTG AGTGAGCTGA TACCGCTCGC CGCAGCCGAA CGACCGAGCG CAGCGAGTCA GTGAGCGAGG AAGCGGAAGA GCGCCTGATG CGGTATTTTC TCCTTACGCA TCTGTGCGGT ATTTCACACC GCATATATGG TGCACTCTCA GTACAATCTG CTCTGATGCC GCATAGTTAA GCCAGTATAC ACTCCGCTAT CGCTACGTGA CTGGGTCATG GCTGCGCCCC GACACCCGCC AACACCCGCT GACGCGCCCT GACGGGCTTG TCTGCTCCCG GCATCCGCTT ACAGACAAGC TGTGACCGTC TCCGGGAGCT GCATGTGTCA GAGGTTTTCA CCGTCATCAC CGAAACGCGC GAGGCAGCTG CGGTAAAGCT CATCAGCGTG GTCGTGAAGC GATTCACAGA TGTCTGCCTG TTCATCCGCG TCCAGCTCGT TGAGTTTCTC CAGAAGCGTT AATGTCTGGC TTCTGATAAA GCGGGCCATG TTAAGGGCGG TTTTTTCCTG TTTGGTCACT GATGCCTCCG TGTAAGGGGG ATTTCTGTTC ATGGGGGTAA TGATACCGAT GAAACGAGAG AGGATGCTCA CGATACGGGT TACTGATGAT GAACATGCCC GGTTACTGGA ACGTTGTGAG GGTAAACAAC TGGCGGTATG GATGCGGCGG GACCAGAGAA AAATCACTCA GGGTCAATGC CAGCGCTTCG TTAATACAGA TGTAGGTGTT CCACAGGGTA GCCAGCAGCA TCCTGCGATG CAGATCCGGA ACATAATGGT GCAGGGCGCT GACTTCCGCG TTTCCAGACT TTACGAAACA CGGAAACCGA AGACCATTCA TGTTGTTGCT CAGGTCGCAG ACGTTTTGCA GCAGCAGTCG CTTCACGTTC GCTCGCGTAT CGGTGATTCA TTCTGCTAAC CAGTAAGGCA ACCCCGCCAG CCTAGCCGGG TCCTCAACGA CAGGAGCACG ATCATGCGCA CCCGTGGCCA GGACCCAACG CTGCCCGAGA TGCGCCGCGT GCGGCTGCTG GAGATGGCGG ACGCGATGGA TATGTTCTGC CAAGGGTTGG TTTGCGCATT CACAGTTCTC CGCAAGAATT GATTGGCTCC AATTCTTGGA GTGGTGAATC CGTTAGCGAG GTGCCGCCGG CTTCCATTCA GGTCGAGGTG GCCCGGCTCC ATGCACCGCG ACGCAACGCG GGGAGGCAGA CAAGGTATAG GGCGGCGCCT ACAATCCATG CCAACCCGTT CCATGTGCTC GCCGAGGCGG CATAAATCGC CGTGACGATC AGCGGTCCAG TGATCGAAGT TAGGCTGGTA AGAGCCGCGA GCGATCCTTG AAGCTGTCCC TGATGGTCGT CATCTACCTG CCTGGACAGC ATGGCCTGCA ACGCGGGCAT CCCGATGCCG CCGGAAGCGA GAAGAATCAT AATGGGGAAG GCCATCCAGC CTCGCGTCGT GAACGCCAGC AAGACGTAGC CCAGCGCGTC GGCCGTAACA ACACCATTTA AATGGAGTGG TTACAAATGG AGTGGTTAAT TAACAACACC ATTTGTCGAC GCTCTCCCTT ATGCGACTCC TGCATTAGGA AGCAGCCCAG TAGTAGGTTG AGGCCGTTGA GCACCGCCGC CGCAAGGAAT GGTGCATGCA AGGAGATGGC GCCCAACAGT CCCCCGGCCA CGGGGCCTGC CACCATACCC ACGCCGAAAC AAGCGCTCAT GAGCCCGAAG TGGCGAGCCC GATCTTCCCC ATCGGTGATG TCGGCGATAT AGGCGCCAGC AACCGCACCT GTGGCGCCGG TGATGCCGGC CACGATGCGT CCGGCGTAGA GGATCGAGAT CTCGATCCCG CGAAATTAAT ACGACTCACT ATAGGGAGAC CACAACGGTT TCCCTCTAGA AATAATTTTG TTTAACTTTA AGAAGGAGAT ATACCATGGC TCATCACCAT CACCATCATA TGGGTACCCT GGAAGCTCAG ACCCAGGGTC CTGGTTCGAT GTCCGCTGTG AAGGTGGCCG TGACGGGTGC GGCTGGTCAG ATCGGGTATG CATTGGTACC GCTGATCGCG CGCGGCGCCC TCCTCGGGCC CACCACGCCT GTGGAGCTCC GCCTGCTGGA TATCGAGCCC GCTCTGAAGG CGCTTGCCGG CGTCGAAGCG GAGCTGGAAG ACTGCGCCTT CCCTCTCCTG GACAAGGTCG TCGTCACGGC AGACCCGCGC GTTGCCTTCG ACGGGGTCGC CATTGCCATC ATGTGCGGTG CCTTCCCGCG CAAGGCAGGG ATGGAGCGCA AGGACCTCCT CGAGATGAAC GCGCGCATCT TCAAGGAGCA GGGTGAGGCC ATCGCTGCTG TGGCCGCGTC AGACTGCCGC GTGGTGGTTG TCGGCAATCC GGCCAACACA AACGCTCTCA TCCTCCTCAA GTCAGCTCAG GGGAAGTTGA ACCCCCGTCA TGTGACCGCC ATGACCCGCC TCGATCACAA CCGTGCCTTG TCTCTTCTGG CTCGCAAGGC CGGTGTGCCG GTGTCGCAGG TGCGCAACGT GATCATCTGG GGCAACCATA GCTCTACACA GGTCCCTGAC ACTGACAGCG CTGTGATCGG CACCACTCCG GCCCGCGAAG CGATCAAGGA CGATGCACTC GATGACGACT TTGTGCAGGT GGTGCGCGGG CGCGGCGCCG AAATCATCCA ACTACGTGGT CTTTCCTCAG CCATGTCCGC CGCCAAGGCC GCCGTAGACC ACGTACATGA CTGGATACAT GGCACACCGG AGGGCGTGTA CGTTTCGATG GGCGTGTACT CGGATGAAAA CCCGTACGGC GTGCCGAGCG GCCTCATCTT CTCCTTTCCG TGCACGTGCC ACGCCGGCGA GTGGACTGTT GTCTCGGGCA AGCTGAATGG GGACCTCGGG AAGCAGCGTC TCGCCAGCAC GATCGCCGAG CTGCAGGAGG AGAGGGCACA GGCAGGGCTA TAAACAGCAC GAACAAGTTC TGCAGCCAAG CTTCTCGAGG ATCCGGCTGC TAACAAAGCC CGAAAGGAAG CTGAGTTGGC TGCTGCCACC GCTGAGCAAT AACTAGCATA ACCCCTTGGG GCCTCTAAAC GGGTCTTGAG GGGTTTTTTG CTGAAAGGAG GAACTATATC CGGATATCCA CAGGACGGGT GTGGTCGCCA TGATCGCGTA GTCGATAGTG GCTCCAAGTA GCGAAGCGAG CAGGACTGGG CGGCGGCCAA AGCGGTCGGA CAGTGCTCCG AGAACGGGTG CGCATAGAAA TTGCATCAAC GCATATAGCG CTAGCAGCAC GCCATAGTGA CTGGCGATGC TGTCGGAATG GACGATATCC CGCAAGAGGC CCGGCAGTAC CGGCATAACC AAGCCTATGC CTACAGCATC CAGGGTGACG GTGCCGAGGA TGACGATGAG CGCATTGTTA GATTTCATAC ACGGTGCCTG ACTGCGTTAG CAATTTAACT GTGATAAACT ACCGCATTAA AGCTTATCGA TGATAAGCTG TCAAACATGA GAA