KlaeA.19615.a
Putative alpha-glucosidase
| CENTER ID: | KlaeA.19615.a |
| ORGANISM: | Klebsiella aerogenes KCTC 2190 |
| ASSOCIATED DISEASE: | |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | False |
| NIH RISK GROUP: | 2 |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
unclassified |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Proteins
| CENTER REFERENCE ID |
DOMAIN/REGION DESCRIPTION |
INFO | AA START |
AA STOP |
ORDER MATERIAL |
|---|---|---|---|---|---|
| KlaeA.19615.a.B1.PW39183 | Full length(KlaeA.19615.a) | 1 | 772 |
Structures
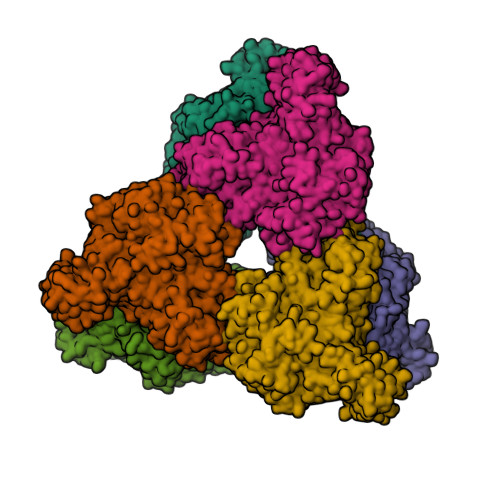
8T7Z
DEPOSITED: 6/21/2023
DETERMINATION: XRay
CLONE: KlaeA.19615.a.B1.GE44874
PROTEIN: KlaeA.19615.a.B1.PW39183
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MKISDGNWLI QPGLNLIQPV QVYEVEQQGN EMVVYAAPRD VRERAWQLDT PLFTLRFFSP QEGIIGVRME HFHGALDNGP HYPLNVQKDV HVEIENTAEF AELKSGSLSV RVTKGEFWAL DFLRDGVRIT GSQLKNNGYV QDSKTQRNYM FERLDLGVGE TVYGLGERFT ALVRNGQTVE TWNEDGGTST EQSYKNIPFY LTNRGYGVLV NHPQRVSFEV GSEKVSKVQF SVEGEYLEYF VIDGPTPKAV LNRYTQFTGR PALPPAWSFG LWLTTSFTTN YDEATVNSFI DGMAERHLPL HVFHFDCFWM KAFQWCDFEW DPLTFPDPEG MIKRLKAKGL KVCVWINPYI GQRSPVFKEL KEKGYLLKRP DGSLWQWDKW QPGLAIYDFT NPEACQWYAS KLKGLVAMGV DCFKTDFGER IPTDVQWFDG SDPQKMHNHY AFIYNELVWK VLKETVGEQE AVLFARSASV GAQQFPVHWG GDCYANYESM AESLRGGLSI GMSGFGFWSH DIGGFENTAP AHVYKRWCAF GLLSSHSRLH GSKSYRVPWA YDEESCDVVR HFTQLKCRMM PYLYRQAALA NEFGTPMLRA MMLEFPDDPA CDYLDRQYML GDSVLVAPVF SEAGEVQFYL PEGRWTHLWH NDELPGSRWH KQRHDALSLP VYVRDNTLLA LGNNDQKPDY AWHEGTAFQL FQLDDGREAL CQVPAADGSV IFTLKAKRQG NTITVSGEGE ARGWTLCLRN IPQIAGVEGG TQAGSELGVV VSAQGNALTI SL
NT Sequence
ATGAAAATCA GTGATGGAAA CTGGCTCATT CAACCAGGGC TCAACCTGAT CCAACCCGTA CAGGTTTACG AGGTGGAGCA GCAGGGGAAT GAAATGGTGG TCTATGCCGC ACCGCGCGAT GTCCGCGAAC GCGCCTGGCA GCTGGATACG CCATTGTTCA CCCTGCGCTT TTTCTCGCCT CAGGAAGGGA TAATCGGCGT GCGCATGGAG CACTTCCATG GCGCGCTGGA TAACGGCCCG CACTATCCGC TGAACGTGCA GAAAGACGTC CATGTCGAAA TAGAAAATAC GGCCGAGTTC GCCGAGCTGA AAAGCGGCAG CCTCAGCGTG CGGGTGACTA AAGGTGAATT CTGGGCGCTG GATTTTCTGC GCGACGGCGT GCGTATCACC GGTAGCCAAC TGAAAAACAA CGGCTACGTG CAGGATAGTA AGACCCAGCG CAACTACATG TTTGAGCGCC TCGACCTCGG CGTCGGCGAA ACCGTCTACG GCCTCGGCGA GCGCTTTACC GCGCTGGTGC GCAACGGCCA GACGGTAGAA ACCTGGAACG AAGACGGCGG CACCAGCACT GAGCAATCCT ACAAAAACAT TCCGTTCTAC CTGACCAACC GCGGCTACGG CGTGCTGGTG AATCACCCGC AGCGCGTCTC CTTCGAGGTG GGCTCGGAGA AAGTCTCTAA AGTCCAGTTC AGCGTTGAAG GCGAATATCT CGAGTACTTC GTGATCGACG GCCCGACGCC GAAAGCGGTG CTTAACCGCT ATACGCAGTT CACCGGCCGC CCGGCGCTGC CGCCGGCATG GTCGTTCGGT CTGTGGCTGA CGACCTCGTT CACTACCAAC TATGACGAAG CGACGGTAAA TAGCTTTATC GACGGCATGG CCGAGCGCCA TCTGCCGCTG CACGTCTTCC ACTTCGACTG CTTCTGGATG AAGGCCTTCC AGTGGTGCGA TTTTGAATGG GATCCGCTAA CTTTCCCGGA CCCGGAAGGG ATGATCAAGC GCCTGAAGGC GAAAGGGCTG AAGGTCTGCG TGTGGATCAA CCCGTACATC GGCCAGCGCT CGCCGGTGTT CAAGGAGCTG AAAGAGAAGG GCTATCTGCT TAAGCGCCCG GACGGTTCGC TGTGGCAGTG GGATAAGTGG CAGCCGGGGC TGGCGATTTA TGACTTCACC AACCCGGAAG CCTGCCAGTG GTACGCCAGC AAGTTAAAAG GTCTGGTAGC GATGGGGGTC GATTGCTTCA AGACCGACTT CGGCGAGCGT ATCCCGACCG ACGTGCAGTG GTTTGACGGT TCCGATCCGC AGAAAATGCA CAACCACTAC GCATTCATCT ATAACGAGCT GGTGTGGAAG GTGCTGAAAG AGACCGTCGG CGAGCAGGAG GCGGTGCTGT TCGCCCGTTC CGCCTCGGTG GGCGCGCAGC AGTTCCCGGT GCACTGGGGC GGCGACTGCT ACGCCAACTA CGAATCGATG GCGGAAAGCC TGCGCGGCGG GCTGTCGATC GGCATGTCCG GCTTCGGTTT CTGGAGCCAC GATATCGGCG GTTTCGAAAA CACCGCGCCG GCCCACGTTT ATAAGCGCTG GTGTGCCTTT GGCCTGCTCT CCAGCCACAG CCGCCTGCAC GGCAGCAAAT CCTATCGTGT GCCGTGGGCC TACGACGAAG AGTCCTGTGA CGTGGTGCGC CACTTCACGC AGCTGAAATG CCGCATGATG CCGTATCTCT ATCGCCAGGC GGCGCTGGCC AACGAGTTCG GCACTCCGAT GTTGCGTGCG ATGATGCTCG AATTCCCGGA CGATCCGGCC TGCGACTATC TCGACCGTCA GTATATGCTC GGCGATTCGG TCCTGGTGGC GCCGGTGTTC TCCGAAGCGG GCGAGGTGCA GTTTTATCTG CCGGAGGGGC GCTGGACGCA CCTGTGGCAT AACGATGAAT TGCCGGGTAG CCGCTGGCAT AAGCAGCGTC ACGATGCACT GAGCCTGCCG GTCTACGTTC GTGACAACAC CCTGCTGGCG CTGGGCAACA ACGACCAGAA ACCCGATTAT GCCTGGCATG AAGGCACCGC CTTCCAGCTG TTCCAGCTCG ACGATGGCCG CGAAGCTCTG TGCCAGGTTC CGGCGGCCGA TGGTTCCGTG ATTTTCACCC TGAAGGCGAA GCGCCAGGGC AACACCATCA CCGTGAGCGG CGAAGGCGAA GCCCGCGGCT GGACGCTGTG TCTGCGCAAT ATCCCGCAGA TAGCGGGCGT GGAGGGTGGG ACGCAGGCGG GCAGCGAACT GGGCGTGGTG GTGAGCGCCC AGGGCAATGC GCTGACGATT TCGCTGTAA
Details for KlaeA.19615.a.B1.PW39183
| PURIFICATION DATe: | 1/10/2023 |
| CONCENTRATION: | 20.7mg/ml |
| OBSERVED MW: | 89kDa |
| EXPRESSION LEVEL: | Moderate Expression |
| PROTEIN PURIFICATION BUFFER: | 25 mM HEPES pH 7.0, 500 mM NaCl, 5% Glycerol, 2 mM DTT, 0.025% Azide |
| EXPRESSION HOST: | BL 21 (DE3) Rosetta |
| VIAL COUNT (approx.): | 20 |
| VIAL VOLUME: | 110µl |
| PERCENT IDENTITY: | 99 |
| PERCENT COVERAGE: | 100 |
Protocol Notes
notes unavailable
Validated AA Sequence
MAHHHHHHMK ISDGNWLIQP GLNLIQPVQV YEVEQQGNEM VVYAAPRDVR ERAWQLDTPL FTLRFFSPQE GIIGVRMEHF QGALDNSPHY PLNVQKDVHV EIENTAEFAE LKSGSLSVRV TKGEFWALDF LRDGVRITGS QLKNNGYVQD SKTQRNYMFE RLDLGVGETV YGLGERFTAL VRNGQTVETW NEDGGTSTEQ SYKNIPFYLT NRGYGVLVNH PQRVSFEVGS EKVSKVQFSV EGEYLEYFVI DGPTPKAVLN RYTQFTGRPA LPPAWSFGLW LTTSFTTNYD EATVNSFIDG MAERHLPLHV FHFDCFWMKA FQWCDFEWDP LTFPDPEGMI KRLKAKGLKV CVWINPYIGQ RSPVFKELKE KGYLLKRPDG SLWQWDKWQP GLAIYDFTNP EACQWYASKL KGLVAMGVDC FKTDFGERIP TDVQWFDGSD PQKMHNHYAF IYNELVWKVL KETVGEQEAV LFARSASVGA QQFPVHWGGD CYANYESMAE SLRGGLSIGM SGFGFWSHDI GGFENTAPAH VYKRWCAFGL LSSHSRLHGS KSYRVPWAYD EESCDVVRHF TQLKCRMMPY LYRQAALANE FGTPMLRAMM LEFPDDPACD YLDRQYMLGD SVLVAPVFSE AGEVQFYLPE GRWTHLWHND ELPGSRWHKQ RHDALSLPVY VRDNTLLALG NNDQKPDYAW HEGTAFQLFQ LGDGNETVCQ VPAADGSAIF TLKAKRQGNT ITVSGEGEAR GWTLCLRNIP QIAGVEGGTQ AGSELGVVVS AQGNALTISL
Validated NT Sequence
atggctcacc accaccacca ccatatgaaa atcagtgatg gaaactggct cattcaacca gggctcaacc tgatccaacc cgtacaggtt tacgaggtgg agcagcaggg gaatgaaatg gtggtctatg ccgcgccacg cgatgtccgc gaacgcgcct ggcagctgga tacgccattg ttcaccctgc gctttttctc gcctcaggaa gggataatcg gcgtgcgcat ggagcacttc cagggcgcgc tggataacag cccgcactat ccgctgaacg tgcagaaaga cgtccatgtc gaaatagaaa atacggccga attcgccgag ctgaaaagtg gcagcctcag cgtgcgggtg actaaaggtg aattttgggc gctggatttt ctgcgcgacg gcgtgcgtat caccggtagc caactgaaaa acaacggcta cgtgcaggat agtaagaccc agcgcaacta catgtttgag cgcctcgacc tcggcgtcgg cgaaaccgtc tacggcctcg gcgagcgctt taccgcgctg gtgcgcaacg gccagacggt agaaacctgg aacgaagacg gcggcaccag caccgagcaa tcctacaaaa acattccgtt ctatctgacc aaccgcggct acggcgtgct ggtgaatcac ccgcagcgcg tctccttcga ggtgggctcg gagaaagtct ctaaagtcca gttcagcgtt gaaggcgaat atctcgagta cttcgtgatc gacggcccga cgccgaaagc ggtgcttaac cgctatacgc agttcaccgg ccgcccggcg ctgccgccgg catggtcgtt cggtctgtgg ctgacgacct cgttcactac caactatgac gaagcgacgg taaatagctt tatcgacggc atggccgagc gccatctgcc gctgcacgtc ttccacttcg actgcttctg gatgaaggcc ttccagtggt gcgattttga atgggatccg ctaactttcc cggacccgga agggatgatc aagcgcctga aggcgaaagg gctgaaggtc tgcgtgtgga tcaacccgta catcggccag cgctcgccgg tgttcaagga gctgaaagag aagggctatc tgcttaagcg cccggacggt tcgctgtggc agtgggataa gtggcagccg gggctggcga tttatgactt caccaacccg gaagcctgcc agtggtacgc cagcaagtta aaaggtctgg tagcgatggg ggtcgattgc ttcaagaccg acttcggcga gcgtatcccg accgacgtgc agtggtttga cggttccgat ccgcagaaaa tgcacaacca ctacgcattc atctataacg agctggtgtg gaaggtgctg aaagagaccg tcggcgagca ggaggcggtg ctgttcgccc gttccgcctc ggtgggcgcg cagcagttcc cggtgcactg gggcggcgac tgctacgcca actacgaatc gatggcggaa agcctgcgcg gcgggctgtc gatcggcatg tccggcttcg gtttctggag ccacgatatc ggcggtttcg aaaacaccgc gccggcccac gtttataagc gctggtgcgc ctttggcctg ctctccagcc acagccgcct gcacggcagc aaatcctatc gtgtgccgtg ggcctacgac gaagagtcct gtgacgtggt gcgccacttc acgcagctga aatgccgcat gatgccgtat ctctatcgcc aggcggcgct ggccaacgag ttcggtactc cgatgttgcg tgcgatgatg ctcgagttcc cggacgatcc ggcctgcgac tatctcgacc gtcagtatat gctcggcgat tcggtcctgg tggcgccggt gttctctgaa gcgggcgagg tgcagtttta tctgccggaa gggcgctgga cgcacctgtg gcataacgat gaattgccgg gtagccgctg gcataagcag cgtcacgatg cactgagcct gccggtctac gttcgtgaca acaccctgct ggcgctgggc aacaacgacc agaaacccga ttatgcctgg catgaaggca ccgccttcca gctgttccag ctgggcgatg gcaatgaaac ggtctgtcag gttccggcgg ccgacggttc cgcgatcttc actctgaagg cgaagcgcca gggtaacacc atcaccgtga gcggcgaagg cgaagcccgc ggctggacgc tgtgtctgcg caatatcccg cagatagcgg gcgtggaggg cgggacgcag gcgggcagcg aactgggcgt ggtggtgagc gcccagggca atgcgctgac gatttcgctg taa
Expressed Protein Sequence
MAHHHHHHMK ISDGNWLIQP GLNLIQPVQV YEVEQQGNEM VVYAAPRDVR ERAWQLDTPL FTLRFFSPQE GIIGVRMEHF HGALDNGPHY PLNVQKDVHV EIENTAEFAE LKSGSLSVRV TKGEFWALDF LRDGVRITGS QLKNNGYVQD SKTQRNYMFE RLDLGVGETV YGLGERFTAL VRNGQTVETW NEDGGTSTEQ SYKNIPFYLT NRGYGVLVNH PQRVSFEVGS EKVSKVQFSV EGEYLEYFVI DGPTPKAVLN RYTQFTGRPA LPPAWSFGLW LTTSFTTNYD EATVNSFIDG MAERHLPLHV FHFDCFWMKA FQWCDFEWDP LTFPDPEGMI KRLKAKGLKV CVWINPYIGQ RSPVFKELKE KGYLLKRPDG SLWQWDKWQP GLAIYDFTNP EACQWYASKL KGLVAMGVDC FKTDFGERIP TDVQWFDGSD PQKMHNHYAF IYNELVWKVL KETVGEQEAV LFARSASVGA QQFPVHWGGD CYANYESMAE SLRGGLSIGM SGFGFWSHDI GGFENTAPAH VYKRWCAFGL LSSHSRLHGS KSYRVPWAYD EESCDVVRHF TQLKCRMMPY LYRQAALANE FGTPMLRAMM LEFPDDPACD YLDRQYMLGD SVLVAPVFSE AGEVQFYLPE GRWTHLWHND ELPGSRWHKQ RHDALSLPVY VRDNTLLALG NNDQKPDYAW HEGTAFQLFQ LDDGREALCQ VPAADGSVIF TLKAKRQGNT ITVSGEGEAR GWTLCLRNIP QIAGVEGGTQ AGSELGVVVS AQGNALTISL
Full NT Sequence (Expression Vector + Insert)
TAATACGACT CACTATAGGG AGACCACAAC GGTTTCCCTC TAGAAATAAT TTTGTTTAAC TTTAAGAAGG AGATATACCA TGGCTCACCA CCACCACCAC CATATGAAAA TCAGTGATGG AAACTGGCTC ATTCAACCAG GGCTCAACCT GATCCAACCC GTACAGGTTT ACGAGGTGGA GCAGCAGGGG AATGAAATGG TGGTCTATGC CGCACCGCGC GATGTCCGCG AACGCGCCTG GCAGCTGGAT ACGCCATTGT TCACCCTGCG CTTTTTCTCG CCTCAGGAAG GGATAATCGG CGTGCGCATG GAGCACTTCC ATGGCGCGCT GGATAACGGC CCGCACTATC CGCTGAACGT GCAGAAAGAC GTCCATGTCG AAATAGAAAA TACGGCCGAG TTCGCCGAGC TGAAAAGCGG CAGCCTCAGC GTGCGGGTGA CTAAAGGTGA ATTCTGGGCG CTGGATTTTC TGCGCGACGG CGTGCGTATC ACCGGTAGCC AACTGAAAAA CAACGGCTAC GTGCAGGATA GTAAGACCCA GCGCAACTAC ATGTTTGAGC GCCTCGACCT CGGCGTCGGC GAAACCGTCT ACGGCCTCGG CGAGCGCTTT ACCGCGCTGG TGCGCAACGG CCAGACGGTA GAAACCTGGA ACGAAGACGG CGGCACCAGC ACTGAGCAAT CCTACAAAAA CATTCCGTTC TACCTGACCA ACCGCGGCTA CGGCGTGCTG GTGAATCACC CGCAGCGCGT CTCCTTCGAG GTGGGCTCGG AGAAAGTCTC TAAAGTCCAG TTCAGCGTTG AAGGCGAATA TCTCGAGTAC TTCGTGATCG ACGGCCCGAC GCCGAAAGCG GTGCTTAACC GCTATACGCA GTTCACCGGC CGCCCGGCGC TGCCGCCGGC ATGGTCGTTC GGTCTGTGGC TGACGACCTC GTTCACTACC AACTATGACG AAGCGACGGT AAATAGCTTT ATCGACGGCA TGGCCGAGCG CCATCTGCCG CTGCACGTCT TCCACTTCGA CTGCTTCTGG ATGAAGGCCT TCCAGTGGTG CGATTTTGAA TGGGATCCGC TAACTTTCCC GGACCCGGAA GGGATGATCA AGCGCCTGAA GGCGAAAGGG CTGAAGGTCT GCGTGTGGAT CAACCCGTAC ATCGGCCAGC GCTCGCCGGT GTTCAAGGAG CTGAAAGAGA AGGGCTATCT GCTTAAGCGC CCGGACGGTT CGCTGTGGCA GTGGGATAAG TGGCAGCCGG GGCTGGCGAT TTATGACTTC ACCAACCCGG AAGCCTGCCA GTGGTACGCC AGCAAGTTAA AAGGTCTGGT AGCGATGGGG GTCGATTGCT TCAAGACCGA CTTCGGCGAG CGTATCCCGA CCGACGTGCA GTGGTTTGAC GGTTCCGATC CGCAGAAAAT GCACAACCAC TACGCATTCA TCTATAACGA GCTGGTGTGG AAGGTGCTGA AAGAGACCGT CGGCGAGCAG GAGGCGGTGC TGTTCGCCCG TTCCGCCTCG GTGGGCGCGC AGCAGTTCCC GGTGCACTGG GGCGGCGACT GCTACGCCAA CTACGAATCG ATGGCGGAAA GCCTGCGCGG CGGGCTGTCG ATCGGCATGT CCGGCTTCGG TTTCTGGAGC CACGATATCG GCGGTTTCGA AAACACCGCG CCGGCCCACG TTTATAAGCG CTGGTGTGCC TTTGGCCTGC TCTCCAGCCA CAGCCGCCTG CACGGCAGCA AATCCTATCG TGTGCCGTGG GCCTACGACG AAGAGTCCTG TGACGTGGTG CGCCACTTCA CGCAGCTGAA ATGCCGCATG ATGCCGTATC TCTATCGCCA GGCGGCGCTG GCCAACGAGT TCGGCACTCC GATGTTGCGT GCGATGATGC TCGAATTCCC GGACGATCCG GCCTGCGACT ATCTCGACCG TCAGTATATG CTCGGCGATT CGGTCCTGGT GGCGCCGGTG TTCTCCGAAG CGGGCGAGGT GCAGTTTTAT CTGCCGGAGG GGCGCTGGAC GCACCTGTGG CATAACGATG AATTGCCGGG TAGCCGCTGG CATAAGCAGC GTCACGATGC ACTGAGCCTG CCGGTCTACG TTCGTGACAA CACCCTGCTG GCGCTGGGCA ACAACGACCA GAAACCCGAT TATGCCTGGC ATGAAGGCAC CGCCTTCCAG CTGTTCCAGC TCGACGATGG CCGCGAAGCT CTGTGCCAGG TTCCGGCGGC CGATGGTTCC GTGATTTTCA CCCTGAAGGC GAAGCGCCAG GGCAACACCA TCACCGTGAG CGGCGAAGGC GAAGCCCGCG GCTGGACGCT GTGTCTGCGC AATATCCCGC AGATAGCGGG CGTGGAGGGT GGGACGCAGG CGGGCAGCGA ACTGGGCGTG GTGGTGAGCG CCCAGGGCAA TGCGCTGACG ATTTCGCTGT GAGTAAGATA GGATCCGGCT GCTAACAAAG CCCGAAAGGA AGCTGAGTTG GCTGCTGCCA CCGCTGAGCA ATAACTAGCA TAACCCCTTG GGGCCTCTAA ACGGGTCTTG AGGGGTTTTT TGCTGAAAGG AGGAACTATA TCCGGATATC CACAGGACGG GTGTGGTCGC CATGATCGCG TAGTCGATAG TGGCTCCAAG TAGCGAAGCG AGCAGGACTG GGCGGCGGCC AAAGCGGTCG GACAGTGCTC CGAGAACGGG TGCGCATAGA AATTGCATCA ACGCATATAG CGCTAGCAGC ACGCCATAGT GACTGGCGAT GCTGTCGGAA TGGACGATAT CCCGCAAGAG GCCCGGCAGT ACCGGCATAA CCAAGCCTAT GCCTACAGCA TCCAGGGTGA CGGTGCCGAG GATGACGATG AGCGCATTGT TAGATTTCAT ACACGGTGCC TGACTGCGTT AGCAATTTAA CTGTGATAAA CTACCGCATT AAAGCTTATC GATGATAAGC TGTCAAACAT GAGAATTCTT GAAGACGAAA GGGCCTCGTG ATACGCCTAT TTTTATAGGT TAATGTCATG ATAATAATGG TTTCTTAGAC GTCAGGTGGC ACTTTTCGGG GAAATGTGCG CGGAACCCCT ATTTGTTTAT TTTTCTAAAT ACATTCAAAT ATGTATCCGC TCATGAGACA ATAACCCTGA TAAATGCTTC AATAATATTG AAAAAGGAAG AGTATGAGTA TTCAACATTT CCGTGTCGCC CTTATTCCCT TTTTTGCGGC ATTTTGCCTT CCTGTTTTTG CTCACCCAGA AACGCTGGTG AAAGTAAAAG ATGCTGAAGA TCAGTTGGGT GCACGAGTGG GTTACATCGA ACTGGATCTC AACAGCGGTA AGATCCTTGA GAGTTTTCGC CCCGAAGAAC GTTTTCCAAT GATGAGCACT TTTAAAGTTC TGCTATGTGG CGCGGTATTA TCCCGTGTTG ACGCCGGGCA AGAGCAACTC GGTCGCCGCA TACACTATTC TCAGAATGAC TTGGTTGAGT ACTCACCAGT CACAGAAAAG CATCTTACGG ATGGCATGAC AGTAAGAGAA TTATGCAGTG CTGCCATAAC CATGAGTGAT AACACTGCGG CCAACTTACT TCTGACAACG ATCGGAGGAC CGAAGGAGCT AACCGCTTTT TTGCACAACA TGGGGGATCA TGTAACTCGC CTTGATCGTT GGGAACCGGA GCTGAATGAA GCCATACCAA ACGACGAGCG TGACACCACG ATGCCTGCAG CAATGGCAAC AACGTTGCGC AAACTATTAA CTGGCGAACT ACTTACTCTA GCTTCCCGGC AACAATTAAT AGACTGGATG GAGGCGGATA AAGTTGCAGG ACCACTTCTG CGCTCGGCCC TTCCGGCTGG CTGGTTTATT GCTGATAAAT CTGGAGCCGG TGAGCGTGGG TCTCGCGGTA TCATTGCAGC ACTGGGGCCA GATGGTAAGC CCTCCCGTAT CGTAGTTATC TACACGACGG GGAGTCAGGC AACTATGGAT GAACGAAATA GACAGATCGC TGAGATAGGT GCCTCACTGA TTAAGCATTG GTAACTGTCA GACCAAGTTT ACTCATATAT ACTTTAGATT GATTTAAAAC TTCATTTTTA ATTTAAAAGG ATCTAGGTGA AGATCCTTTT TGATAATCTC ATGACCAAAA TCCCTTAACG TGAGTTTTCG TTCCACTGAG CGTCAGACCC CGTAGAAAAG ATCAAAGGAT CTTCTTGAGA TCCTTTTTTT CTGCGCGTAA TCTGCTGCTT GCAAACAAAA AAACCACCGC TACCAGCGGT GGTTTGTTTG CCGGATCAAG AGCTACCAAC TCTTTTTCCG AAGGTAACTG GCTTCAGCAG AGCGCAGATA CCAAATACTG TCCTTCTAGT GTAGCCGTAG TTAGGCCACC ACTTCAAGAA CTCTGTAGCA CCGCCTACAT ACCTCGCTCT GCTAATCCTG TTACCAGTGG CTGCTGCCAG TGGCGATAAG TCGTGTCTTA CCGGGTTGGA CTCAAGACGA TAGTTACCGG ATAAGGCGCA GCGGTCGGGC TGAACGGGGG GTTCGTGCAC ACAGCCCAGC TTGGAGCGAA CGACCTACAC CGAACTGAGA TACCTACAGC GTGAGCTATG AGAAAGCGCC ACGCTTCCCG AAGGGAGAAA GGCGGACAGG TATCCGGTAA GCGGCAGGGT CGGAACAGGA GAGCGCACGA GGGAGCTTCC AGGGGGAAAC GCCTGGTATC TTTATAGTCC TGTCGGGTTT CGCCACCTCT GACTTGAGCG TCGATTTTTG TGATGCTCGT CAGGGGGGCG GAGCCTATGG AAAAACGCCA GCAACGCGGC CTTTTTACGG TTCCTGGCCT TTTGCTGGCC TTTTGCTCAC ATGTTCTTTC CTGCGTTATC CCCTGATTCT GTGGATAACC GTATTACCGC CTTTGAGTGA GCTGATACCG CTCGCCGCAG CCGAACGACC GAGCGCAGCG AGTCAGTGAG CGAGGAAGCG GAAGAGCGCC TGATGCGGTA TTTTCTCCTT ACGCATCTGT GCGGTATTTC ACACCGCATA TATGGTGCAC TCTCAGTACA ATCTGCTCTG ATGCCGCATA GTTAAGCCAG TATACACTCC GCTATCGCTA CGTGACTGGG TCATGGCTGC GCCCCGACAC CCGCCAACAC CCGCTGACGC GCCCTGACGG GCTTGTCTGC TCCCGGCATC CGCTTACAGA CAAGCTGTGA CCGTCTCCGG GAGCTGCATG TGTCAGAGGT TTTCACCGTC ATCACCGAAA CGCGCGAGGC AGCTGCGGTA AAGCTCATCA GCGTGGTCGT GAAGCGATTC ACAGATGTCT GCCTGTTCAT CCGCGTCCAG CTCGTTGAGT TTCTCCAGAA GCGTTAATGT CTGGCTTCTG ATAAAGCGGG CCATGTTAAG GGCGGTTTTT TCCTGTTTGG TCACTGATGC CTCCGTGTAA GGGGGATTTC TGTTCATGGG GGTAATGATA CCGATGAAAC GAGAGAGGAT GCTCACGATA CGGGTTACTG ATGATGAACA TGCCCGGTTA CTGGAACGTT GTGAGGGTAA ACAACTGGCG GTATGGATGC GGCGGGACCA GAGAAAAATC ACTCAGGGTC AATGCCAGCG CTTCGTTAAT ACAGATGTAG GTGTTCCACA GGGTAGCCAG CAGCATCCTG CGATGCAGAT CCGGAACATA ATGGTGCAGG GCGCTGACTT CCGCGTTTCC AGACTTTACG AAACACGGAA ACCGAAGACC ATTCATGTTG TTGCTCAGGT CGCAGACGTT TTGCAGCAGC AGTCGCTTCA CGTTCGCTCG CGTATCGGTG ATTCATTCTG CTAACCAGTA AGGCAACCCC GCCAGCCTAG CCGGGTCCTC AACGACAGGA GCACGATCAT GCGCACCCGT GGCCAGGACC CAACGCTGCC CGAGATGCGC CGCGTGCGGC TGCTGGAGAT GGCGGACGCG ATGGATATGT TCTGCCAAGG GTTGGTTTGC GCATTCACAG TTCTCCGCAA GAATTGATTG GCTCCAATTC TTGGAGTGGT GAATCCGTTA GCGAGGTGCC GCCGGCTTCC ATTCAGGTCG AGGTGGCCCG GCTCCATGCA CCGCGACGCA ACGCGGGGAG GCAGACAAGG TATAGGGCGG CGCCTACAAT CCATGCCAAC CCGTTCCATG TGCTCGCCGA GGCGGCATAA ATCGCCGTGA CGATCAGCGG TCCAGTGATC GAAGTTAGGC TGGTAAGAGC CGCGAGCGAT CCTTGAAGCT GTCCCTGATG GTCGTCATCT ACCTGCCTGG ACAGCATGGC CTGCAACGCG GGCATCCCGA TGCCGCCGGA AGCGAGAAGA ATCATAATGG GGAAGGCCAT CCAGCCTCGC GTCGCGAACG CCAGCAAGAC GTAGCCCAGC GCGTCGGCCG CCATGCCGGC GATAATGGCC TGCTTCTCGC CGAAACGTTT GGTGGCGGGA CCAGTGACGA AGGCTTGAGC GAGGGCGTGC AAGATTCCGA ATACCGCAAG CGACAGGCCG ATCATCGTCG CGCTCCAGCG AAAGCGGTCC TCGCCGAAAA TGACCCAGAG CGCTGCCGGC ACCTGTCCTA CGAGTTGCAT GATAAAGAAG ACAGTCATAA GTGCGGCGAC GATAGTCATG CCCCGCGCCC ACCGGAAGGA GCTGACTGGG TTGAAGGCTC TCAAGGGCAT CGGTCGACGC TCTCCCTTAT GCGACTCCTG CATTAGGAAG CAGCCCAGTA GTAGGTTGAG GCCGTTGAGC ACCGCCGCCG CAAGGAATGG TGCATGCAAG GAGATGGCGC CCAACAGTCC CCCGGCCACG GGGCCTGCCA CCATACCCAC GCCGAAACAA GCGCTCATGA GCCCGAAGTG GCGAGCCCGA TCTTCCCCAT CGGTGATGTC GGCGATATAG GCGCCAGCAA CCGCACCTGT GGCGCCGGTG ATGCCGGCCA CGATGCGTCC GGCGTAGAGG ATCGAGATCT CGATCCCGCG AAAT