KlaeA.00139.a
Dephospho-CoA kinase
| CENTER ID: | KlaeA.00139.a |
| ORGANISM: | Klebsiella aerogenes KCTC 2190 |
| ASSOCIATED DISEASE: | |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | False |
| NIH RISK GROUP: | 2 |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
unclassified |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Proteins
| CENTER REFERENCE ID |
DOMAIN/REGION DESCRIPTION |
INFO | AA START |
AA STOP |
ORDER MATERIAL |
|---|---|---|---|---|---|
| KlaeA.00139.a.B1.PW39166 | Full length(KlaeA.00139.a) | 1 | 206 |
Structures
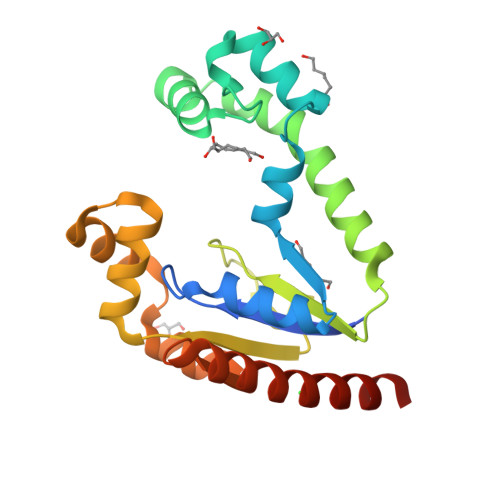
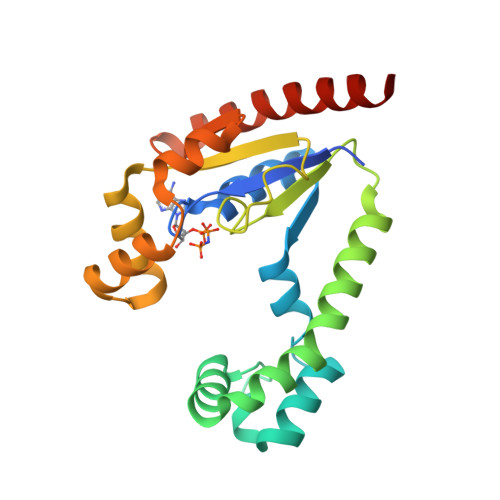
8SBN
DEPOSITED: 4/3/2023
DETERMINATION: XRay
CLONE: KlaeA.00139.a.B1.GE44837
PROTEIN: KlaeA.00139.a.B1.PW39166
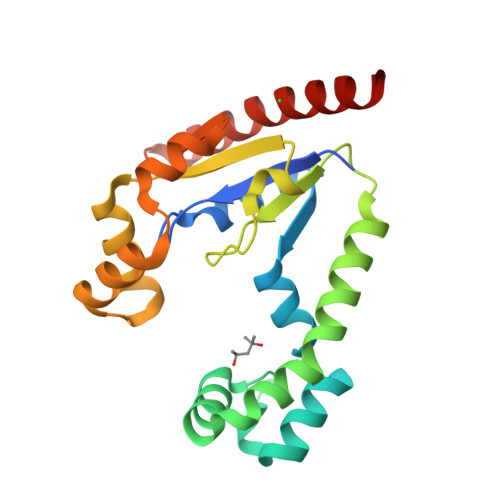
8SBO
DEPOSITED: 4/3/2023
DETERMINATION: XRay
CLONE: KlaeA.00139.a.B1.GE44837
PROTEIN: KlaeA.00139.a.B1.PW39166
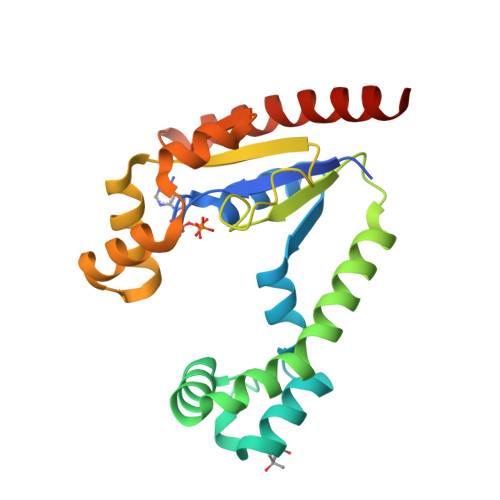
8U94
DEPOSITED: 9/18/2023
DETERMINATION: XRay
CLONE: KlaeA.00139.a.B1.GE44837
PROTEIN: KlaeA.00139.a.B1.PW39166
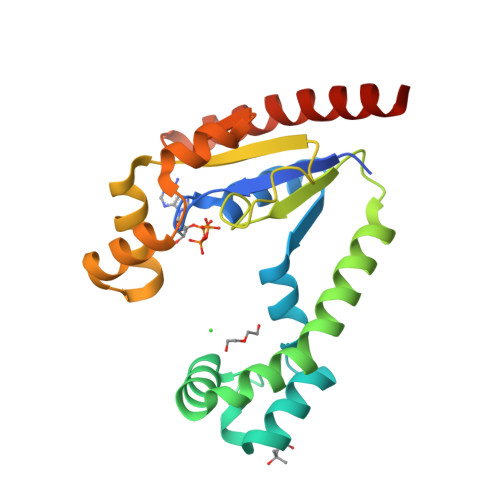
8U96
DEPOSITED: 9/18/2023
DETERMINATION: XRay
CLONE: KlaeA.00139.a.B1.GE44837
PROTEIN: KlaeA.00139.a.B1.PW39166
8U97
DEPOSITED: 9/18/2023
DETERMINATION: XRay
CLONE: KlaeA.00139.a.B1.GE44837
PROTEIN: KlaeA.00139.a.B1.PW39166
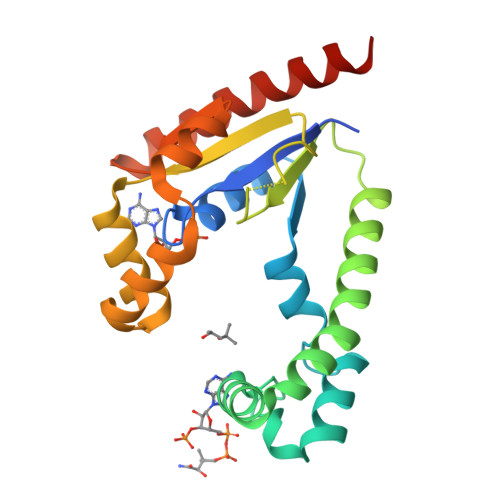
9BKZ
DEPOSITED: 4/29/2024
DETERMINATION: XRay
CLONE: KlaeA.00139.a.B1.GE44837
PROTEIN: KlaeA.00139.a.B1.PW39166
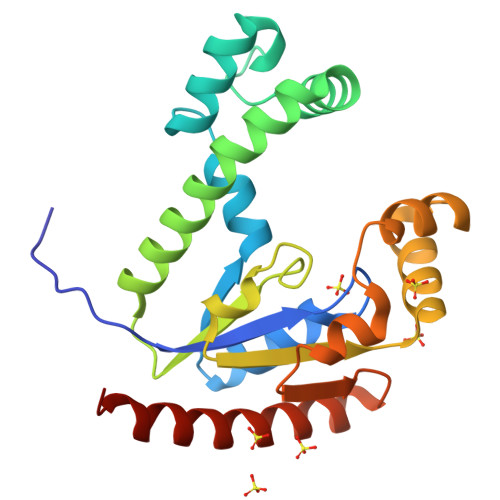
9DUG
DEPOSITED: 10/2/2024
DETERMINATION: XRay
CLONE: KlaeA.00139.a.B1.GE44837
PROTEIN: KlaeA.00139.a.B1.PW39166
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MTYTVALTGG IGSGKSTVAD AFSHLGVNVI DADIIARQVV EPGTPGLNAI AQRFGPQILN KDGTLNRRAL REHIFAHAED KNWLNALLHP QIQQETRRQM LLATSSYILW VVPLLVENRL SAKADRVLVV DVPKETQIAR TMLRDRVSRQ HAEHILAAQA TREQRLAVAD DVIENMGSPD AIASAVARLH AKYQQLATQA ASQEKP
NT Sequence
ATGACATACA CGGTAGCGTT AACAGGCGGC ATCGGTAGCG GTAAAAGTAC CGTAGCCGAC GCATTCTCAC ACCTCGGGGT TAACGTTATT GATGCTGACA TTATCGCGCG CCAGGTGGTC GAGCCCGGTA CCCCGGGGCT AAACGCGATT GCTCAACGCT TCGGTCCGCA GATCCTGAAT AAAGATGGCA CCCTTAACCG TCGCGCTCTG CGTGAGCATA TTTTCGCTCA CGCAGAGGAT AAGAACTGGC TAAACGCGCT GCTGCACCCG CAAATTCAGC AGGAAACGCG TCGCCAGATG CTGCTTGCCA CCTCGTCTTA TATTCTCTGG GTTGTACCTT TACTGGTCGA AAACCGTTTG TCCGCCAAAG CCGATCGGGT TCTTGTTGTC GATGTGCCGA AAGAGACGCA AATAGCGCGC ACGATGCTTC GCGATCGGGT CAGTCGGCAA CATGCGGAAC ATATTCTTGC CGCTCAGGCA ACGCGCGAAC AGCGCCTTGC CGTTGCGGAT GATGTTATTG AAAATATGGG TTCACCTGAT GCCATCGCAT CAGCTGTCGC CCGCCTGCAT GCAAAGTATC AACAGCTGGC AACGCAGGCC GCCTCACAGG AAAAACCGTA A
Details for KlaeA.00139.a.B1.PW39166
| PURIFICATION DATe: | 12/13/2022 |
| CONCENTRATION: | 24.83mg/ml |
| OBSERVED MW: | 24kDa |
| EXPRESSION LEVEL: | Moderate Expression |
| PROTEIN PURIFICATION BUFFER: | 25 mM HEPES pH 7.0, 500 mM NaCl, 5% Glycerol, 2 mM DTT, 0.025% Azide |
| EXPRESSION HOST: | BL 21 (DE3) Rosetta |
| VIAL COUNT (approx.): | 19 |
| VIAL VOLUME: | 110µl |
| PERCENT IDENTITY: | 83 |
| PERCENT COVERAGE: | 100 |
Protocol Notes
notes unavailable
Validated AA Sequence
MAHHHHHHMT YTVALTGGIG SGKSTVADEF AHLGVTVIDA DIIARQVVEP GTPALLAIAE RFGPQMINDD GSLNRRRLRE RIFAHSEDKA WLNALLHPLI QQETRRQMQA STSPYLLWVV PLLVENRLTD KADRILVVDV PKETQIERTI RRDGVSREHA EHILAAQATR EQRLAAADDV IENMGSADAV ASHVARLHDK YLMLASQAAS QEKP
Validated NT Sequence
atggctcacc accaccacca ccatatgaca tacacggtag cgttaacagg cggcatcggt agcggtaaaa gtaccgtcgc cgacgaattt gctcacctgg gcgtaaccgt catcgacgcc gatattattg cgcgtcaggt tgtagagccc ggtactcccg ccctgcttgc tatcgctgaa aggtttggtc cacagatgat caacgacgat ggcagtctga atcgccgccg cttacgcgaa cgcatttttg cgcatagcga ggacaaggcc tggcttaacg cgctgctgca tccgctgatt cagcaagaaa cgcgccgtca gatgcaggcc tcaacctcac cttatctcct ctgggtcgta cccttgctgg tcgaaaaccg cctgaccgat aaagccgatc gcatactggt tgtcgatgtg ccaaaagaga cgcaaatcga gcgcaccata cgccgcgatg gggtcagtcg tgaacacgct gaacatattc ttgccgccca ggcgacgcgc gaacagcgtc ttgccgcagc ggatgatgtt attgaaaaca tgggctccgc ggatgccgtc gcatcccacg tcgcccgcct gcacgataag tatttaatgc tggcatcgca ggccgcctca caggaaaaac cgtaa
Expressed Protein Sequence
MAHHHHHHMT YTVALTGGIG SGKSTVADAF SHLGVNVIDA DIIARQVVEP GTPGLNAIAQ RFGPQILNKD GTLNRRALRE HIFAHAEDKN WLNALLHPQI QQETRRQMLL ATSSYILWVV PLLVENRLSA KADRVLVVDV PKETQIARTM LRDRVSRQHA EHILAAQATR EQRLAVADDV IENMGSPDAI ASAVARLHAK YQQLATQAAS QEKP
Full NT Sequence (Expression Vector + Insert)
TAATACGACT CACTATAGGG AGACCACAAC GGTTTCCCTC TAGAAATAAT TTTGTTTAAC TTTAAGAAGG AGATATACCA TGGCTCACCA CCACCACCAC CATATGACAT ACACGGTAGC GTTAACAGGC GGCATCGGTA GCGGTAAAAG TACCGTAGCC GACGCATTCT CACACCTCGG GGTTAACGTT ATTGATGCTG ACATTATCGC GCGCCAGGTG GTCGAGCCCG GTACCCCGGG GCTAAACGCG ATTGCTCAAC GCTTCGGTCC GCAGATCCTG AATAAAGATG GCACCCTTAA CCGTCGCGCT CTGCGTGAGC ATATTTTCGC TCACGCAGAG GATAAGAACT GGCTAAACGC GCTGCTGCAC CCGCAAATTC AGCAGGAAAC GCGTCGCCAG ATGCTGCTTG CCACCTCGTC TTATATTCTC TGGGTTGTAC CTTTACTGGT CGAAAACCGT TTGTCCGCCA AAGCCGATCG GGTTCTTGTT GTCGATGTGC CGAAAGAGAC GCAAATAGCG CGCACGATGC TTCGCGATCG GGTCAGTCGG CAACATGCGG AACATATTCT TGCCGCTCAG GCAACGCGCG AACAGCGCCT TGCCGTTGCG GATGATGTTA TTGAAAATAT GGGTTCACCT GATGCCATCG CATCAGCTGT CGCCCGCCTG CATGCAAAGT ATCAACAGCT GGCAACGCAG GCCGCCTCAC AGGAAAAACC GTGAGTAAGA TAGGATCCGG CTGCTAACAA AGCCCGAAAG GAAGCTGAGT TGGCTGCTGC CACCGCTGAG CAATAACTAG CATAACCCCT TGGGGCCTCT AAACGGGTCT TGAGGGGTTT TTTGCTGAAA GGAGGAACTA TATCCGGATA TCCACAGGAC GGGTGTGGTC GCCATGATCG CGTAGTCGAT AGTGGCTCCA AGTAGCGAAG CGAGCAGGAC TGGGCGGCGG CCAAAGCGGT CGGACAGTGC TCCGAGAACG GGTGCGCATA GAAATTGCAT CAACGCATAT AGCGCTAGCA GCACGCCATA GTGACTGGCG ATGCTGTCGG AATGGACGAT ATCCCGCAAG AGGCCCGGCA GTACCGGCAT AACCAAGCCT ATGCCTACAG CATCCAGGGT GACGGTGCCG AGGATGACGA TGAGCGCATT GTTAGATTTC ATACACGGTG CCTGACTGCG TTAGCAATTT AACTGTGATA AACTACCGCA TTAAAGCTTA TCGATGATAA GCTGTCAAAC ATGAGAATTC TTGAAGACGA AAGGGCCTCG TGATACGCCT ATTTTTATAG GTTAATGTCA TGATAATAAT GGTTTCTTAG ACGTCAGGTG GCACTTTTCG GGGAAATGTG CGCGGAACCC CTATTTGTTT ATTTTTCTAA ATACATTCAA ATATGTATCC GCTCATGAGA CAATAACCCT GATAAATGCT TCAATAATAT TGAAAAAGGA AGAGTATGAG TATTCAACAT TTCCGTGTCG CCCTTATTCC CTTTTTTGCG GCATTTTGCC TTCCTGTTTT TGCTCACCCA GAAACGCTGG TGAAAGTAAA AGATGCTGAA GATCAGTTGG GTGCACGAGT GGGTTACATC GAACTGGATC TCAACAGCGG TAAGATCCTT GAGAGTTTTC GCCCCGAAGA ACGTTTTCCA ATGATGAGCA CTTTTAAAGT TCTGCTATGT GGCGCGGTAT TATCCCGTGT TGACGCCGGG CAAGAGCAAC TCGGTCGCCG CATACACTAT TCTCAGAATG ACTTGGTTGA GTACTCACCA GTCACAGAAA AGCATCTTAC GGATGGCATG ACAGTAAGAG AATTATGCAG TGCTGCCATA ACCATGAGTG ATAACACTGC GGCCAACTTA CTTCTGACAA CGATCGGAGG ACCGAAGGAG CTAACCGCTT TTTTGCACAA CATGGGGGAT CATGTAACTC GCCTTGATCG TTGGGAACCG GAGCTGAATG AAGCCATACC AAACGACGAG CGTGACACCA CGATGCCTGC AGCAATGGCA ACAACGTTGC GCAAACTATT AACTGGCGAA CTACTTACTC TAGCTTCCCG GCAACAATTA ATAGACTGGA TGGAGGCGGA TAAAGTTGCA GGACCACTTC TGCGCTCGGC CCTTCCGGCT GGCTGGTTTA TTGCTGATAA ATCTGGAGCC GGTGAGCGTG GGTCTCGCGG TATCATTGCA GCACTGGGGC CAGATGGTAA GCCCTCCCGT ATCGTAGTTA TCTACACGAC GGGGAGTCAG GCAACTATGG ATGAACGAAA TAGACAGATC GCTGAGATAG GTGCCTCACT GATTAAGCAT TGGTAACTGT CAGACCAAGT TTACTCATAT ATACTTTAGA TTGATTTAAA ACTTCATTTT TAATTTAAAA GGATCTAGGT GAAGATCCTT TTTGATAATC TCATGACCAA AATCCCTTAA CGTGAGTTTT CGTTCCACTG AGCGTCAGAC CCCGTAGAAA AGATCAAAGG ATCTTCTTGA GATCCTTTTT TTCTGCGCGT AATCTGCTGC TTGCAAACAA AAAAACCACC GCTACCAGCG GTGGTTTGTT TGCCGGATCA AGAGCTACCA ACTCTTTTTC CGAAGGTAAC TGGCTTCAGC AGAGCGCAGA TACCAAATAC TGTCCTTCTA GTGTAGCCGT AGTTAGGCCA CCACTTCAAG AACTCTGTAG CACCGCCTAC ATACCTCGCT CTGCTAATCC TGTTACCAGT GGCTGCTGCC AGTGGCGATA AGTCGTGTCT TACCGGGTTG GACTCAAGAC GATAGTTACC GGATAAGGCG CAGCGGTCGG GCTGAACGGG GGGTTCGTGC ACACAGCCCA GCTTGGAGCG AACGACCTAC ACCGAACTGA GATACCTACA GCGTGAGCTA TGAGAAAGCG CCACGCTTCC CGAAGGGAGA AAGGCGGACA GGTATCCGGT AAGCGGCAGG GTCGGAACAG GAGAGCGCAC GAGGGAGCTT CCAGGGGGAA ACGCCTGGTA TCTTTATAGT CCTGTCGGGT TTCGCCACCT CTGACTTGAG CGTCGATTTT TGTGATGCTC GTCAGGGGGG CGGAGCCTAT GGAAAAACGC CAGCAACGCG GCCTTTTTAC GGTTCCTGGC CTTTTGCTGG CCTTTTGCTC ACATGTTCTT TCCTGCGTTA TCCCCTGATT CTGTGGATAA CCGTATTACC GCCTTTGAGT GAGCTGATAC CGCTCGCCGC AGCCGAACGA CCGAGCGCAG CGAGTCAGTG AGCGAGGAAG CGGAAGAGCG CCTGATGCGG TATTTTCTCC TTACGCATCT GTGCGGTATT TCACACCGCA TATATGGTGC ACTCTCAGTA CAATCTGCTC TGATGCCGCA TAGTTAAGCC AGTATACACT CCGCTATCGC TACGTGACTG GGTCATGGCT GCGCCCCGAC ACCCGCCAAC ACCCGCTGAC GCGCCCTGAC GGGCTTGTCT GCTCCCGGCA TCCGCTTACA GACAAGCTGT GACCGTCTCC GGGAGCTGCA TGTGTCAGAG GTTTTCACCG TCATCACCGA AACGCGCGAG GCAGCTGCGG TAAAGCTCAT CAGCGTGGTC GTGAAGCGAT TCACAGATGT CTGCCTGTTC ATCCGCGTCC AGCTCGTTGA GTTTCTCCAG AAGCGTTAAT GTCTGGCTTC TGATAAAGCG GGCCATGTTA AGGGCGGTTT TTTCCTGTTT GGTCACTGAT GCCTCCGTGT AAGGGGGATT TCTGTTCATG GGGGTAATGA TACCGATGAA ACGAGAGAGG ATGCTCACGA TACGGGTTAC TGATGATGAA CATGCCCGGT TACTGGAACG TTGTGAGGGT AAACAACTGG CGGTATGGAT GCGGCGGGAC CAGAGAAAAA TCACTCAGGG TCAATGCCAG CGCTTCGTTA ATACAGATGT AGGTGTTCCA CAGGGTAGCC AGCAGCATCC TGCGATGCAG ATCCGGAACA TAATGGTGCA GGGCGCTGAC TTCCGCGTTT CCAGACTTTA CGAAACACGG AAACCGAAGA CCATTCATGT TGTTGCTCAG GTCGCAGACG TTTTGCAGCA GCAGTCGCTT CACGTTCGCT CGCGTATCGG TGATTCATTC TGCTAACCAG TAAGGCAACC CCGCCAGCCT AGCCGGGTCC TCAACGACAG GAGCACGATC ATGCGCACCC GTGGCCAGGA CCCAACGCTG CCCGAGATGC GCCGCGTGCG GCTGCTGGAG ATGGCGGACG CGATGGATAT GTTCTGCCAA GGGTTGGTTT GCGCATTCAC AGTTCTCCGC AAGAATTGAT TGGCTCCAAT TCTTGGAGTG GTGAATCCGT TAGCGAGGTG CCGCCGGCTT CCATTCAGGT CGAGGTGGCC CGGCTCCATG CACCGCGACG CAACGCGGGG AGGCAGACAA GGTATAGGGC GGCGCCTACA ATCCATGCCA ACCCGTTCCA TGTGCTCGCC GAGGCGGCAT AAATCGCCGT GACGATCAGC GGTCCAGTGA TCGAAGTTAG GCTGGTAAGA GCCGCGAGCG ATCCTTGAAG CTGTCCCTGA TGGTCGTCAT CTACCTGCCT GGACAGCATG GCCTGCAACG CGGGCATCCC GATGCCGCCG GAAGCGAGAA GAATCATAAT GGGGAAGGCC ATCCAGCCTC GCGTCGCGAA CGCCAGCAAG ACGTAGCCCA GCGCGTCGGC CGCCATGCCG GCGATAATGG CCTGCTTCTC GCCGAAACGT TTGGTGGCGG GACCAGTGAC GAAGGCTTGA GCGAGGGCGT GCAAGATTCC GAATACCGCA AGCGACAGGC CGATCATCGT CGCGCTCCAG CGAAAGCGGT CCTCGCCGAA AATGACCCAG AGCGCTGCCG GCACCTGTCC TACGAGTTGC ATGATAAAGA AGACAGTCAT AAGTGCGGCG ACGATAGTCA TGCCCCGCGC CCACCGGAAG GAGCTGACTG GGTTGAAGGC TCTCAAGGGC ATCGGTCGAC GCTCTCCCTT ATGCGACTCC TGCATTAGGA AGCAGCCCAG TAGTAGGTTG AGGCCGTTGA GCACCGCCGC CGCAAGGAAT GGTGCATGCA AGGAGATGGC GCCCAACAGT CCCCCGGCCA CGGGGCCTGC CACCATACCC ACGCCGAAAC AAGCGCTCAT GAGCCCGAAG TGGCGAGCCC GATCTTCCCC ATCGGTGATG TCGGCGATAT AGGCGCCAGC AACCGCACCT GTGGCGCCGG TGATGCCGGC CACGATGCGT CCGGCGTAGA GGATCGAGAT CTCGATCCCG CGAAAT