InvbM.18715.a
Hemagglutinin (HA)
| CENTER ID: | InvbM.18715.a |
| ORGANISM: | Influenzavirus A Influenza A virus A/Netherlands/002P1/1951 |
| ASSOCIATED DISEASE: | |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | True |
| NIH RISK GROUP: | 2 |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
IIIC |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Proteins
| CENTER REFERENCE ID |
DOMAIN/REGION DESCRIPTION |
INFO | AA START |
AA STOP |
ORDER MATERIAL |
|---|---|---|---|---|---|
| InvbM.18715.a.KN11.PD38309 | full length | 18 | 509 |
Structures
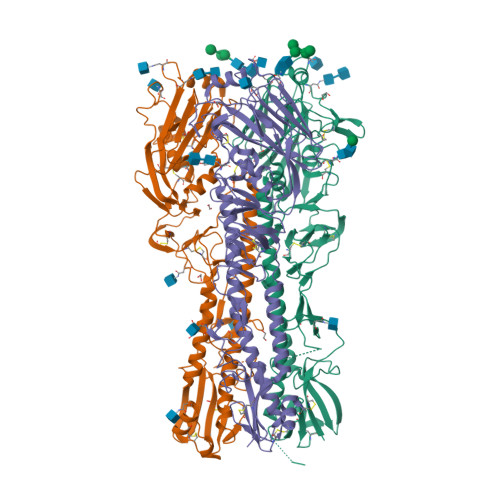
6N41
DEPOSITED: 11/16/2018
DETERMINATION: XRay
CLONE: InvbM.18715.a.KN11.GE42180
PROTEIN: InvbM.18715.a.KN11.PD38309
Publications by SSGCID
Structural characterisation of hemagglutinin from seven Influenza A H1N1 strains reveal diversity in the C05 antibody recognition site
Abendroth J, Baydo RO, Edwards TE, Lorimer DD, Forwood JK, Conrady DG, Stigliano M, Ghafoori SM, Calhoun BM, Peterson GF, Grice RL
Sci Rep - 2023
volume 13, issue 1, pages 6940
PMID: 37117205; PMCID: PMC10140725
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MKANLLVLLC ALAAADADTI CIGYHANNST DTVDTVLEKN VTVTHSVNLL EDSHNGKLCR LKGKAPLQLG KCNIAGWILG NPECESLLSK RSWSYIAETP NSENGTCYPG DFADYEELRE QLSSVSSFER FEIFPKESSW PKHNTTRGVT AACSHARKSS FYKNLLWLTE ANGSYPNLSK SYVNNQEKEV LVLWGVHHPS NIEDQRTLYR KENAYVSVVS SNYNRRFTPE IAERPKVRNQ AGRMNYYWTL LEPGDTIIFE ANGNLIAPWY AFALSRGLGS GIITSNASMD ECDTKCQTPQ GAINSSLPFQ NIHPVTIGEC PKYVKSTKLR MVTGLRNIPS IQSRGLFGAI AGFIEGGWTG MMDGWYGYHH QNEQGSGYAA DQKSTQNAIN GITNKVNSVI EKMNTQFTAV GKEFNKLEKR MENLNKKVDD GFLDIWTYNA ELLVLLENER TLDFHDSNVK NLYEKVKNQL RNNAKELGNG CFEFYHKCDN ECMESVKNGT YDYPKYSEES KLNREKIDGV KLESMGVYQI LAIYSTVASS LVLLVSLGAI SFWMCSNGSL QCRICI
NT Sequence
atgaaggcaa acctactggt cctgttatgt gcacttgcag ctgcagatgc agacacaata tgtataggct accatgcgaa caactcaacc gacactgttg acacagtact cgaaaagaat gtgacagtga cacactctgt aaacctactc gaagacagcc acaacgggaa attatgcaga ttaaaaggaa aagccccact acaattgggg aaatgtaaca ttgccggatg gatcttagga aacccagaat gcgaatcact gctttccaaa agatcatggt cctacattgc agaaacacca aactctgaga atggaacatg ttacccagga gatttcgccg actatgagga attgagggag caattgagct cagtatcatc tttcgagaga ttcgaaatat tccccaagga aagttcatgg cccaaacaca acacaaccag aggagtgacg gcagcatgct cccatgcgag gaaaagcagt ttttacaaaa atttgctctg gctgacggag gcaaatggct catacccaaa tctgagcaag tcctatgtga acaatcaaga gaaagaagtc cttgtgctat ggggtgttca tcacccgtct aacatagagg atcaaaggac cctctatcgg aaagaaaatg cttatgtctc tgtagtgtct tcaaattata acaggagatt caccccagaa atagcagaaa ggcccaaagt aagaaatcaa gcagggagaa tgaactatta ctggactttg ctagaacccg gagacacaat aatatttgag gcaaatggaa atctaatagc accatggtat gctttcgcac tgagtagagg ccttggatca ggaatcatca cctcaaacgc atcaatggat gaatgtgaca cgaagtgtca aacaccccag ggagctataa acagtagtct cccttttcag aatatacacc cagtcacaat aggagagtgc ccaaaatacg taaagagtac aaaattgaga atggttacag gactaaggaa cataccatcc attcaatcca ggggtctatt tggagccatt gccggtttca ttgaaggggg atggactggg atgatggatg gatggtatgg ttaccatcat cagaatgaac agggatctgg ctatgctgcg gatcaaaaaa gcacacaaaa tgccattaac gggattacaa ataaggtgaa ctctgttatc gagaaaatga acactcaatt cacagctgtg ggtaaagaat tcaacaaatt agaaaaaaga atggaaaact taaataaaaa agttgatgat ggatttctgg atatttggac atataatgca gaattgttag ttctactgga aaatgaaagg actttggatt tccatgactc aaatgtgaag aatctgtatg agaaagtaaa aaaccaatta aggaataatg caaaggaact aggaaacggg tgttttgagt tctatcacaa gtgtgacaat gaatgcatgg aaagtgtaaa aaatggaact tatgattacc caaaatattc agaggaatca aagttaaaca gggaaaagat tgatggagtg aaattggaat caatgggggt ctatcagatt ctggcgatct actcaactgt cgccagttca ctggtgcttt tggtctccct gggggcaatc agtttctgga tgtgttctaa tggatctttg cagtgcagaa tatgcatctg a
Details for InvbM.18715.a.KN11.PD38309
| PURIFICATION DATe: | 3/26/2018 |
| CONCENTRATION: | 10.4mg/ml |
| OBSERVED MW: | 65kDa |
| EXPRESSION LEVEL: | Moderate Expression |
| PROTEIN PURIFICATION BUFFER: | 25 mM Tris pH 8.0, 150 mM NaCl |
| EXPRESSION HOST: | Sf9 cells (ES) |
| VIAL COUNT (approx.): | 5 |
| VIAL VOLUME: | 50µl |
| PERCENT IDENTITY: | data unavailable |
| PERCENT COVERAGE: | data unavailable |
Protocol Notes
notes unavailable
Validated AA Sequence
sequence unavailable
Validated NT Sequence
sequence unavailable
Expressed Protein Sequence
MVLVNQSHQG FNKEHTSKMV SAIVLYVLLA AAAHSAFAGS DTICIGYHAN NSTDTVDTVL EKNVTVTHSV NLLEDSHNGK LCRLKGKAPL QLGKCNIAGW ILGNPECESL LSKRSWSYIA ETPNSENGTC YPGDFADYEE LREQLSSVSS FERFEIFPKE SSWPKHNTTR GVTAACSHAR KSSFYKNLLW LTEANGSYPN LSKSYVNNQE KEVLVLWGVH HPSNIEDQRT LYRKENAYVS VVSSNYNRRF TPEIAERPKV RNQAGRMNYY WTLLEPGDTI IFEANGNLIA PWYAFALSRG LGSGIITSNA SMDECDTKCQ TPQGAINSSL PFQNIHPVTI GECPKYVKST KLRMVTGLRN IPSIQSRGLF GAIAGFIEGG WTGMMDGWYG YHHQNEQGSG YAADQKSTQN AINGITNKVN SVIEKMNTQF TAVGKEFNKL EKRMENLNKK VDDGFLDIWT YNAELLVLLE NERTLDFHDS NVKNLYEKVK NQLRNNAKEL GNGCFEFYHK CDNECMESVK NGTYDYPKYS EEFLVPRGSP GSGYIPEAPR DGQAYVRKDG EWVLLSTFLG HHHHHH
Full NT Sequence (Expression Vector + Insert)
GGAACGGCTC CGCCCACTAT TAATGAAATT AAAAATTCCA ATTTTAAAAA ACGCAGCAAG AGAAACATTT GTATGAAAGA ATGCGTAGAA GGAAAGAAAA ATGTCGTCGA CATGCTGAAC AACAAGATTA ATATGCCTCC GTGTATAAAA AAAATATTGA ACGATTTGAA AGAAAACAAT GTACCGCGCG GCGGTATGTA CAGGAAGAGG TTTATACTAA ACTGTTACAT TGCAAACGTG GTTTCGTGTG CCAAGTGTGA AAACCGATGT TTAATCAAGG CTCTGACGCA TTTCTACAAC CACGACTCCA AGTGTGTGGG TGAAGTCATG CATCTTTTAA TCAAATCCCA AGATGTGTAT AAACCACCAA ACTGCCAAAA AATGAAAACT GTCGACAAGC TCTGTCCGTT TGCTGGCAAC TGCAAGGGTC TCAATCCTAT TTGTAATTAT TGAATAATAA AACAATTATA AATGCTAAAT TTGTTTTTTA TTAACGATAC AAACCAAACG CAACAAGAAC ATTTGTAGTA TTATCTATAA TTGAAAACGC GTAGTTATAA TCGCTGAGGT AATATTTAAA ATCATTTTCA AATGATTCAC AGTTAATTTG CGACAATATA ATTTTATTTT CACATAAACT AGACGCCTTG TCGTCTTCTT CTTCGTATTC CTTCTCTTTT TCATTTTTCT CTTCATAAAA ATTAACATAG TTATTATCGT ATCCATATAT GTATCTATCG TATAGAGTAA ATTTTTTGTT GTCATAAATA TATATGTCTT TTTTAATGGG GTGTATAGTA CCGCTGCGCA TAGTTTTTCT GTAATTTACA ACAGTGCTAT TTTCTGGTAG TTCTTCGGAG TGTGTTGCTT TAATTATTAA ATTTATATAA TCAATGAATT TGGGATCGTC GGTTTTGTAC AATATGTTGC CGGCATAGTA CGCAGCTTCT TCTAGTTCAA TTACACCATT TTTTAGCAGC ACCGGATTAA CATAACTTTC CAAAATGTTG TACGAACCGT TAAACAAAAA CAGTTCACCT CCCTTTTCTA TACTATTGTC TGCGAGCAGT TGTTTGTTGT TAAAAATAAC AGCCATTGTA ATGAGACGCA CAAACTAATA TCACAAACTG GAAATGTCTA TCAATATATA GTTGCTGATC AGATCCTCAT TGTTTGCCTC CCTGCTGCGG TTTTTCACCG AAGTTCATGC CAGTCCAGCG TTTTTGCAGC AGAAAAGCCG CCGACTTCGG TTTGCGGTCG CGAGTGAAGA TCCCTTTCTT GTTACCGCCA ACGCGCAATA TGCCTTGCGA GGTCGCAAAA TCGGCGAAAT TCCATACCTG TTCACCGACG ACGGCGCTGA CGCGATCAAA GACGCGGTGA TACATATCCA GCCATGCACA CTGATACTCT TCACTCCACA TGTCGGTGTA CATTGAGTGC AGCCCGGCTA ACGTATCCAC GCCGTATTCG GTGATGATAA TCGGCTGATG CAGTTTCTCC TGCCAGGCCA GAAGTTCTTT TTCCAGTACC TTCTCTGCCG TTTCCAAATC GCCGCTTTGG ACATACCATC CGTAATAACG GTTCAGGCAC AGCACATCAA AGAGATCGCT GATGGTATCG GTGTGAGCGT CGCAGAACAT TACATTGACG CAGGTGATCG GACGCGTCGG GTCGAGTTTA CGCGTTGCTT CCGCCAGTGG CGCGAAATAT TCCCGTGCAC CTTGCGGACG GGTATCCGGT TCGTTGGCAA TACTCCACAT CACCACGCTT GGGTGGTTTT TGTCACGCGC TATCAGCTCT TTAATCGCCT GTAAGTGCGC TTGCTGAGTT TCCCCGTTGA CTGCCTCTTC GCTGTACAGT TCTTTCGGCT TGTTGCCCGC TTCGAAACCA ATGCCTAAAG AGAGCGAAAA GCCGACAGCA GCAGTTTCAT CAATCACCAC GATGCCATGT TCATCTGCCC AGTCGAGCAT CTCTTCAGCG TAAGGGTAAT GCGAGGTACG GTAGGAGTTG GCCCCAATCC AGTCCATTAA TGCGTGGTCG TGCACCATCA GCACGTTATC GAATCCTTTG CCACGTAAGT CCGCATCTTC ATGACGACCA AAGCCAGTAA AGTAGAACGG TTTGTGGTTA ATCAGGAACT GTTGGCCCTT CACTGCCACT GACCGGATGC CGACGCGAAG CGGGTAGATA TCACACTCTG TCTGGCTTTT GGCTGTGACG CACAGTTCAT AGAGATAACC TTCACCCGGT TGCCAGAGGT GCGGATTCAC CACTTGCAAA GTCCCGCTAG TGCCTTGTCC AGTTGCAACC ACCTGTTGAT CCGCATCACG CAGTTCAACG CTGACATCAC CATTGGCCAC CACCTGCCAG TCAACAGACG CGTGGTTACA GTCTTGCGCG ACATGCGTCA CCACGGTGAT ATCGTCCACC CAGGTGTTCG GCGTGGTGTA GAGCATTACG CTGCGATGGA TTCCGGCATA GTTAAAGAAA TCATGGAAGT AAGACTGCTT TTTCTTGCCG TTTTCGTCGG TAATCACCAT TCCCGGCGGG ATAGTCTGCC AGTTCAGTTC GTTGTTCACA CAAACGGTGA TACGTACACT TTTCCCGGCA ATAACATACG GCGTGACATC GGCTTCAAAT GGCGTATAGC CGCCCTGATG CTCCATCACT TCCTGATTAT TGACCCACAC TTTGCCGTAA TGAGTGACCG CATCGAAACG CAGCACGATA CGCTGGCCTG CCCAACCTTT CGGTATAAAG ACTTCGCGCT GATACCAGAC GTTGCCCGCA TAATTACGAA TATCTGCATC GGCGAACTGA TCGTTAAAAC TGCCTGGCAC AGCAATTGCC CGGCTTTCTT GTAACGCGCT TTCCCACCAA CGCTGATCAA TTCCACAGTT TTCGCGATCC AGACTGAATG CCCACAGGCC GTCGAGTTTT TTGATTTCAC GGGTTGGGGT TTCTACAGGA CGGACCATAT TTATAGGTGT AATTTATGTA GCTGTAATTT TTACCTTATT AATATTTTTT ACGCTTTGCA TTCGACGACT GAACTCCCAA ATATATGTTT AACTCGTCTT GGTCGTTTGA ATTTTTGTTG CTGTGTTTCC TAATATTTTC CATCACCTTA AATATGTTAT TGTAATCCTC AATGTTGAAC TTGCAATTGG ACACGGCATA GTTTTCCATA GTCGTGTAAA ACATGGTATT GGCTGCATTG TAATACATCC GACTGAGCGG GTACGGATCT ATGTGTTTGA GCAGCCTGTT CAAAAACTCT GCATCGTCGC AAAACGGAAT TTCGTCGACA GATCTGATCA TGGAGATAAT TAAAATGATA ACCATCTCGC AAATAAATAA GTATTTTACT GTTTTCGTAA CAGTTTTGTA ATAAAAAAAC CTATAAATAT AGGATCTATG GTACTAGTTA ATCAGTCTCA CCAAGGATTC AACAAGGAAC ATACATCAAA GATGGTGTCG GCAATCGTGT TATATGTGCT TCTGGCCGCT GCCGCCCACT CTGCGTTCGC TGGATCCGAC ACCATCTGCA TCGGATACCA CGCCAACAAC TCTACCGACA CCGTCGACAC TGTCCTGGAA AAGAACGTCA CCGTCACTCA CTCTGTCAAC CTGTTGGAGG ACTCTCACAA CGGAAAGCTG TGCAGGCTGA AGGGAAAAGC CCCTCTGCAG CTGGGAAAGT GCAACATTGC CGGATGGATC TTGGGAAACC CCGAATGCGA ATCTCTGCTG TCTAAGCGCT CTTGGTCTTA CATTGCTGAA ACCCCTAACT CCGAGAACGG AACTTGCTAC CCTGGCGACT TCGCCGACTA CGAAGAACTG AGGGAACAGC TGTCCTCTGT CTCTTCTTTC GAACGCTTCG AAATCTTCCC CAAAGAGTCC TCTTGGCCCA AGCACAACAC CACCAGAGGT GTCACTGCTG CCTGCTCTCA CGCTAGGAAG TCTAGCTTCT ACAAGAACCT GCTGTGGCTG ACCGAAGCCA ACGGATCTTA CCCCAACCTG TCTAAGTCCT ACGTCAACAA TCAAGAGAAA GAGGTCCTGG TCCTCTGGGG AGTCCACCAT CCTTCTAACA TCGAGGACCA GCGCACCCTG TACCGCAAAG AAAACGCCTA CGTCAGCGTC GTCAGCTCTA ACTACAACAG GCGCTTCACC CCTGAAATCG CCGAAAGGCC TAAAGTCCGC AACCAGGCCG GAAGGATGAA CTACTACTGG ACCCTGTTGG AACCCGGCGA CACTATCATC TTCGAGGCCA ACGGAAACCT GATCGCCCCT TGGTACGCTT TCGCTCTGTC TCGTGGACTC GGATCTGGAA TCATCACCTC TAACGCCTCT ATGGACGAAT GCGACACCAA GTGCCAGACT CCTCAGGGTG CTATCAACTC TAGCCTGCCT TTCCAGAACA TTCACCCCGT CACCATCGGA GAATGCCCCA AATACGTCAA GTCTACCAAG CTGAGGATGG TTACCGGACT GAGGAACATC CCCTCTATCC AGTCTAGGGG ACTGTTCGGA GCTATCGCCG GATTCATCGA AGGCGGATGG ACCGGAATGA TGGACGGATG GTACGGTTAC CACCACCAAA ACGAACAAGG ATCTGGATAC GCCGCCGACC AGAAGTCTAC CCAGAACGCC ATCAACGGAA TCACCAACAA AGTCAACTCC GTCATCGAGA AGATGAACAC CCAGTTCACC GCCGTCGGAA AAGAGTTCAA CAAGCTGGAA AAGCGCATGG AAAACCTGAA CAAGAAGGTC GACGACGGAT TCCTGGACAT CTGGACCTAC AACGCCGAAC TGCTGGTCCT GCTGGAAAAC GAAAGGACCC TGGACTTCCA CGACTCTAAC GTCAAGAACC TCTACGAGAA AGTGAAGAAC CAGCTGCGCA ACAACGCCAA AGAACTCGGA AACGGATGCT TCGAGTTCTA CCACAAGTGC GACAACGAGT GCATGGAATC TGTCAAGAAC GGCACCTACG ACTACCCCAA GTACTCTGAA GAATTCCTCG TACCACGGGG TAGTCCAGGA TCTGGATATA TCCCGGAGGC CCCAAGAGAT GGACAGGCAT ACGTGCGGAA GGATGGCGAA TGGGTGCTGT TGTCGACGTT TCTTGGCCAT CATCACCATC ACCACTGATA AGGTCACCAC CACCACCACC ACTAAAAGCT TGCGGCCGCA CTCGAGCCTA GGTAGCTGAG CGCATGCAAG CTGATCCGGG TTATTAGTAC ATTTATTAAG CGCTAGATTC TGTGCGTTGT TGATTTACAG ACAATTGTTG TACGTATTTT AATAATTCAT TAAATTTATA ATCTTTAGGG TGGTATGTTA GAGCGAAAAT CAAATGATTT TCAGCGTCTT TATATCTGAA TTTAAATATT AAATCCTCAA TAGATTTGTA AAATAGGTTT CGATTAGTTT CAAACAAGGG TTGTTTTTCC GAACCGATGG CTGGACTATC TAATGGATTT TCGCTCAACG CCACAAAACT TGCCAAATCT TGTAGCAGCA ATCTAGCTTT GTCGATATTC GTTTGTGTTT TGTTTTGTAA TAAAGGTTCG ACGTCGTTCA AAATATTATG CGCTTTTGTA TTTCTTTCAT CACTGTCGTT AGTGTACAAT TGACTCGACG TAAACACGTT AAATAGAGCT TGGACATATT TAACATCGGG CGTGTTAGCT TTATTAGGCC GATTATCGTC GTCGTCCCAA CCCTCGTCGT TAGAAGTTGC TTCCGAAGAC GATTTTGCCA TAGCCACACG ACGCCTATTA ATTGTGTCGG CTAACACGTC CGCGATCAAA TTTGTAGTTG AGCTTTTTGG AATTATTTCT GATTGCGGGC GTTTTTGGGC GGGTTTCAAT CTAACTGTGC CCGATTTTAA TTCAGACAAC ACGTTAGAAA GCGATGGTGC AGGCGGTGGT AACATTTCAG ACGGCAAATC TACTAATGGC GGCGGTGGTG GAGCTGATGA TAAATCTACC ATCGGTGGAG GCGCAGGCGG GGCTGGCGGC GGAGGCGGAG GCGGAGGTGG TGGCGGTGAT GCAGACGGCG GTTTAGGCTC AAATGTCTCT TTAGGCAACA CAGTCGGCAC CTCAACTATT GTACTGGTTT CGGGCGCCGT TTTTGGTTTG ACCGGTCTGA GACGAGTGCG ATTTTTTTCG TTTCTAATAG CTTCCAACAA TTGTTGTCTG TCGTCTAAAG GTGCAGCGGG TTGAGGTTCC GTCGGCATTG GTGGAGCGGG CGGCAATTCA GACATCGATG GTGGTGGTGG TGGTGGAGGC GCTGGAATGT TAGGCACGGG AGAAGGTGGT GGCGGCGGTG CCGCCGGTAT AATTTGTTCT GGTTTAGTTT GTTCGCGCAC GATTGTGGGC ACCGGCGCAG GCGCCGCTGG CTGCACAACG GAAGGTCGTC TGCTTCGAGG CAGCGCTTGG GGTGGTGGCA ATTCAATATT ATAATTGGAA TACAAATCGT AAAAATCTGC TATAAGCATT GTAATTTCGC TATCGTTTAC CGTGCCGATA TTTAACAACC GCTCAATGTA AGCAATTGTA TTGTAAAGAG ATTGTCTCAA GCTCGGATCG ATCCCGCACG CCGATAACAA GCCTTTTCAT TTTTACTACA GCATTGTAGT GGCGAGACAC TTCGCTGTCG TCGAGGTTTA AACGCTTCCT CGCTCACTGA CTCGCTGCGC TCGGTCGTTC GGCTGCGGCG AGCGGTATCA GCTCACTCAA AGGCGGTAAT ACGGTTATCC ACAGAATCAG GGGATAACGC AGGAAAGAAC ATGTGAGCAA AAGGCCAGCA AAAGGCCAGG AACCGTAAAA AGGCCGCGTT GCTGGCGTTT TTCCATAGGC TCCGCCCCCC TGACGAGCAT CACAAAAATC GACGCTCAAG TCAGAGGTGG CGAAACCCGA CAGGACTATA AAGATACCAG GCGTTTCCCC CTGGAAGCTC CCTCGTGCGC TCTCCTGTTC CGACCCTGCC GCTTACCGGA TACCTGTCCG CCTTTCTCCC TTCGGGAAGC GTGGCGCTTT CTCATAGCTC ACGCTGTAGG TATCTCAGTT CGGTGTAGGT CGTTCGCTCC AAGCTGGGCT GTGTGCACGA ACCCCCCGTT CAGCCCGACC GCTGCGCCTT ATCCGGTAAC TATCGTCTTG AGTCCAACCC GGTAAGACAC GACTTATCGC CACTGGCAGC AGCCACTGGT AACAGGATTA GCAGAGCGAG GTATGTAGGC GGTGCTACAG AGTTCTTGAA GTGGTGGCCT AACTACGGCT ACACTAGAAG GACAGTATTT GGTATCTGCG CTCTGCTGAA GCCAGTTACC TTCGGAAAAA GAGTTGGTAG CTCTTGATCC GGCAAACAAA CCACCGCTGG TAGCGGTGGT TTTTTTGTTT GCAAGCAGCA GATTACGCGC AGAAAAAAAG GATCTCAAGA AGATCCTTTG ATCTTTTCTA CGGGGTCTGA CGCTCAGTGG AACGAAAACT CACGTTAAGG GATTTTGGTC ATGAGATTAT CAAAAAGGAT CTTCACCTAG ATCCTTTTAA ATTAAAAATG AAGTTTTAAA TCAATCTAAA GTATATATGA GTAAACTTGG TCTGACAGTT ACCAATGCTT AATCAGTGAG GCACCTATCT CAGCGATCTG TCTATTTCGT TCATCCATAG TTGCCTGACT CCCCGTCGTG TAGATAACTA CGATACGGGA GGGCTTACCA TCTGGCCCCA GTGCTGCAAT GATACCGCGA GACCCACGCT CACCGGCTCC AGATTTATCA GCAATAAACC AGCCAGCCGG AAGGGCCGAG CGCAGAAGTG GTCCTGCAAC TTTATCCGCC TCCATCCAGT CTATTAATTG TTGCCGGGAA GCTAGAGTAA GTAGTTCGCC AGTTAATAGT TTGCGCAACG TTGTTGCCAT TGCTACAGGC ATCGTGGTGT CACGCTCGTC GTTTGGTATG GCTTCATTCA GCTCCGGTTC CCAACGATCA AGGCGAGTTA CATGATCCCC CATGTTGTGC AAAAAAGCGG TTAGCTCCTT CGGTCCTCCG ATCGTTGTCA GAAGTAAGTT GGCCGCAGTG TTATCACTCA TGGTTATGGC AGCACTGCAT AATTCTCTTA CTGTCATGCC ATCCGTAAGA TGCTTTTCTG TGACTGGTGA GTACTCAACC AAGTCATTCT GAGAATAGTG TATGCGGCGA CCGAGTTGCT CTTGCCCGGC GTCAATACGG GATAATACCG CGCCACATAG CAGAACTTTA AAAGTGCTCA TCATTGGAAA ACGTTCTTCG GGGCGAAAAC TCTCAAGGAT CTTACCGCTG TTGAGATCCA GTTCGATGTA ACCCACTCGT GCACCCAACT GATCTTCAGC ATCTTTTACT TTCACCAGCG TTTCTGGGTG AGCAAAAACA GGAAGGCAAA ATGCCGCAAA AAAGGGAATA AGGGCGACAC GGAAATGTTG AATACTCATA CTCTTCCTTT TTCAATATTA TTGAAGCATT TATCAGGGTT ATTGTCTCAT GAGCGGATAC ATATTTGAAT GTATTTAGAA AAATAAACAA ATAGGGGTTC CGCGCACATT TCCCCGAAAA GTGCCACCTG ACGCGCCCTG TAGCGGCGCA TTAAGCGCGG CGGGTGTGGT GGTTACGCGC AGCGTGACCG CTACACTTGC CAGCGCCCTA GCGCCCGCTC CTTTCGCTTT CTTCCCTTCC TTTCTCGCCA CGTTCGCCGG CTTTCCCCGT CAAGCTCTAA ATCGGGGGCT CCCTTTAGGG TTCCGATTTA GTGCTTTACG GCACCTCGAC CCCAAAAAAC TTGATTAGGG TGATGGTTCA CGTAGTGGGC CATCGCCCTG ATAGACGGTT TTTCGCCCTT TGACGTTGGA GTCCACGTTC TTTAATAGTG GACTCTTGTT CCAAACTGGA ACAACACTCA ACCCTATCTC GGTCTATTCT TTTGATTTAT AAGGGATTTT GCCGATTTCG GCCTATTGGT TAAAAAATGA GCTGATTTAA CAAAAATTTA ACGCGAATTT TAACAAAATA TTAACGTTTA CAATTTCCCA TTCGCCATTC AGGCTGCGCA ACTGTTGGGA AGGGCGATCG GTGCGGGCCT CTTCGCTATT ACGCCA