HosaA.01062.a
Dihydrofolate reductase (DHFR)
| CENTER ID: | HosaA.01062.a |
| ORGANISM: | Homo sapiens |
| ASSOCIATED DISEASE: | |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | True |
| NIH RISK GROUP: | unclassified |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
unclassified |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Structures
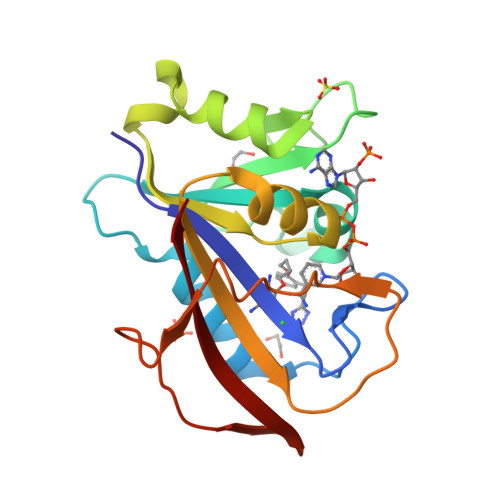
5SD6
DEPOSITED: 12/20/2021
DETERMINATION: XRay
CLONE: HosaA.01062.a.A1.GE44261
PROTEIN: HosaA.01062.a.A1.PW38972
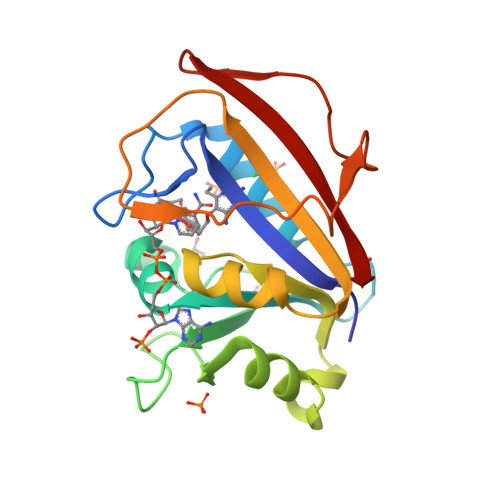
5SD7
DEPOSITED: 12/20/2021
DETERMINATION: XRay
CLONE: HosaA.01062.a.A1.GE44261
PROTEIN: HosaA.01062.a.A1.PW38972
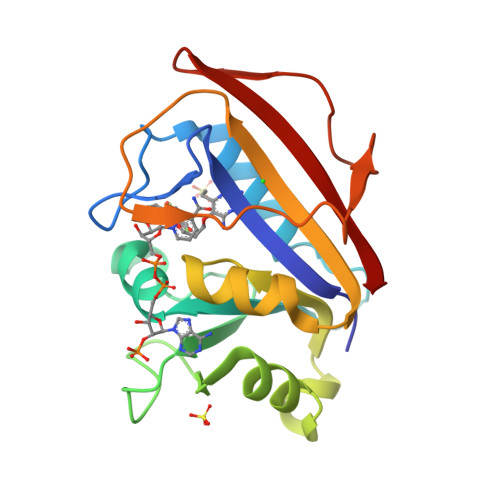
5SD8
DEPOSITED: 12/20/2021
DETERMINATION: XRay
CLONE: HosaA.01062.a.A1.GE44261
PROTEIN: HosaA.01062.a.A1.PW38972
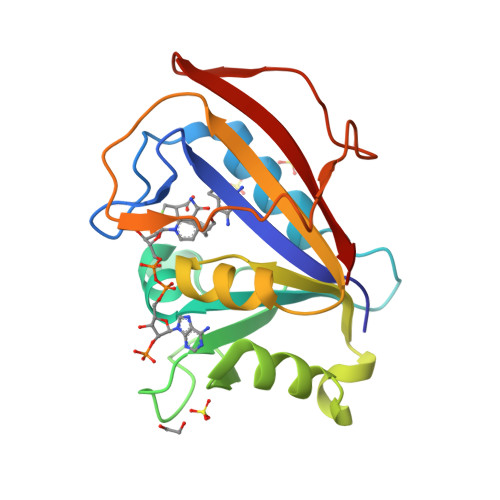
5SD9
DEPOSITED: 12/20/2021
DETERMINATION: XRay
CLONE: HosaA.01062.a.A1.GE44261
PROTEIN: HosaA.01062.a.A1.PW38972
5SDB
DEPOSITED: 12/20/2021
DETERMINATION: XRay
CLONE: HosaA.01062.a.A1.GE44261
PROTEIN: HosaA.01062.a.A1.PW38972
5SDA
DEPOSITED: 12/20/2021
DETERMINATION: XRay
CLONE: HosaA.01062.a.A1.GE44261
PROTEIN: HosaA.01062.a.A1.PW38972
External Resources
| RESOURCE | REFERENCE ID |
|---|---|
| UniProt: | P00374 |
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MVGSLNCIVA VSQNMGIGKN GDLPWPPLRN EFRYFQRMTT TSSVEGKQNL VIMGKKTWFS IPEKNRPLKG RINLVLSREL KEPPQGAHFL SRSLDDALKL TEQPELANKV DMVWIVGGSS VYKEAMNHPG HLKLFVTRIM QDFESDTFFP EIDLEKYKLL PEYPGVLSDV QEEKGIKYKF EVYEKND
NT Sequence
atggttggtt cgctaaactg catcgtcgct gtgtcccaga acatgggcat cggcaagaac ggggacctgc cctggccacc gctcaggaat gaattcagat atttccagag aatgaccaca acctcttcag tagaaggtaa acagaatctg gtgattatgg gtaagaagac ctggttctcc attcctgaga agaatcgacc tttaaagggt agaattaatt tagttctcag cagagaactc aaggaacctc cacaaggagc tcattttctt tccagaagtc tagatgatgc cttaaaactt actgaacaac cagaattagc aaataaagta gacatggtct ggatagttgg tggcagttct gtttataagg aagccatgaa tcacccaggc catcttaaac tatttgtgac aaggatcatg caagactttg aaagtgacac gttttttcca gaaattgatt tggagaaata taaacttctg ccagaatacc caggtgttct ctctgatgtc caggaggaga aaggcattaa gtacaaattt gaagtatatg agaagaatga ttaa