EscoB.07059.a
Putative type VI secretion protein (TssK)
| CENTER ID: | EscoB.07059.a |
| ORGANISM: | Escherichia coli 042 |
| ASSOCIATED DISEASE: | |
| CURRENT STATUS: | in PDB |
| COMMUNITY REQUEST: | False |
| NIH RISK GROUP: | 1 |
| SELECT AGENT: | False |
| NIH PRIORITY pathogens category: |
IIIB |
Ordering Clones & Proteins
If there are materials available for this target, they will be listed below.
Materials can be ordered from SSGCID using the button in the "order material" column.
Clicking the button will add the material to a virtual cart.
You may order multiple materials at a time at no cost to you, as this contract is funded
by NIAID. When you are ready to place your order, click the "Place Order" link which will
appear in the top right corner of the page after you place your first item in your cart.
Structures
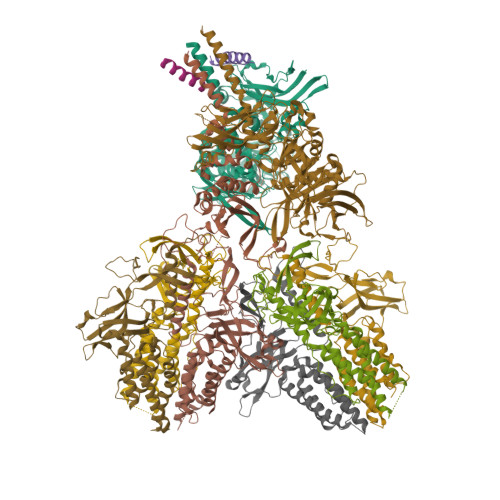
6N38
DEPOSITED: 11/14/2018
DETERMINATION: CryoEM
CLONE: EscoB.07059.a.K2.GE43013
PROTEIN: EscoB.07059.a.K2.PE00007
Publications by SSGCID
Structure of the type VI secretion system TssK-TssF-TssG baseplate subcomplex revealed by cryo-electron microscopy
Veesler D, Park YJ, Lacourse KD, Cambillau C, DiMaio F, Mougous JD
Nat Commun - 2018
volume 9, issue 1, pages 5385
PMID: 30568167; PMCID: PMC6300606
PDB:
6N38
External Resources
| RESOURCE | REFERENCE ID |
|---|---|
| BV-BRC: | fig|216592.3.peg.4703 |
| UniProt: | D3GU39 |
Sequences
These sequences are the native gene sequence; sequences of constructs derived from these sequences may differ due to codon optimization or other protocols.
To find the specific sequence of any material you may have ordered, click on the "info" button next to the name of that material.
AA Sequence
MKIYRPLWED GAFLMPQQFQ QQAAWDVHLA DSVARMGLAH PWGVVAAEFD DSLLPLSRLN ATRLIVRFPD GTLIDTERAD NLPPVCDLST VSDRSLVDIV LALPLLNANG GNLDNGSESE RPRRWKSERV NVQELAGHEQ SEVAVLRHNL TLRMAHQENA AWLTCPVTRL VRDAQGQWCR DPRFIPPLLT LSASPSLMTE LAELLHHLQA RRQRLMSMRR ENNARLADFA VADVSLFWLL NALNSAEPVL KELLDMPYRH PELLYRELAR LAGSLLTFSL EHNVDAVPAY HHETPENVFP PLLSLLNRLL EASLPSRVVF IELKQKGVMW EGALHDARLR EGADFWLSVR SSMPGHELQT KFPQLCKAGS PDDVSEVVNV ALSGVIIRPV THVPAAIPLR LENQYFALDL STDAARAMLD AGRCTFYTPA SLGDVKLELF AVLRT
NT Sequence
ATGAAGATTT ATCGCCCATT ATGGGAAGAC GGGGCTTTTC TGATGCCCCA GCAGTTTCAG CAGCAGGCTG CCTGGGATGT TCATCTGGCA GACAGCGTTG CCAGAATGGG GCTGGCGCAT CCATGGGGCG TGGTGGCTGC AGAGTTTGAT GACTCTCTGT TACCGCTTTC ACGGTTGAAT GCCACCCGTC TGATTGTTCG TTTCCCGGAC GGAACGCTTA TTGATACGGA ACGCGCGGAT AATCTGCCTC CGGTCTGTGA TTTATCGACG GTTTCTGATC GTTCCCTGGT GGATATTGTG CTGGCACTAC CGTTACTGAA TGCTAACGGT GGCAACCTTG ATAATGGCAG TGAGAGCGAG CGTCCGCGTC GCTGGAAATC AGAAAGGGTG AATGTGCAGG AGCTGGCCGG GCATGAGCAA AGCGAAGTGG CGGTATTGCG GCATAACCTG ACTCTGCGCA TGGCTCATCA GGAAAATGCT GCCTGGCTGA CCTGTCCCGT TACCCGTCTT GTTCGTGATG CACAGGGACA GTGGTGCAGG GACCCGCGTT TTATTCCCCC TCTGCTGACG CTGTCTGCCA GTCCTTCGCT GATGACTGAA CTTGCGGAGT TGCTTCATCA CCTGCAGGCG CGTCGCCAGC GACTGATGTC CATGCGTCGG GAGAACAATG CCCGTCTTGC GGATTTTGCT GTGGCGGACG TGTCGTTGTT CTGGTTGCTG AATGCCCTGA ACAGTGCGGA GCCTGTTCTG AAAGAGTTGC TTGACATGCC TTACCGCCAC CCGGAACTGT TGTACAGGGA GCTTGCCCGG CTGGCAGGCT CCCTGCTCAC ATTCTCGCTT GAGCATAATG TGGATGCGGT TCCGGCATAC CATCATGAAA CACCTGAAAA TGTTTTCCCA CCATTGCTTT CTTTGCTGAA CCGGCTGCTG GAGGCAAGCC TGCCTTCCCG TGTGGTTTTC ATTGAACTGA AACAAAAGGG TGTGATGTGG GAGGGGGCAT TACATGATGC GCGTCTGCGC GAAGGGGCTG ATTTCTGGCT TTCAGTGCGC TCTTCCATGC CCGGGCATGA ACTGCAGACG AAGTTTCCGC AGCTATGCAA AGCCGGGAGC CCCGATGATG TGTCTGAGGT GGTGAATGTG GCGCTGAGCG GGGTCATTAT CCGTCCGGTT ACGCATGTAC CGGCGGCCAT TCCGCTCCGG CTGGAAAACC AGTATTTCGC GCTGGATTTA AGTACGGATG CGGCCCGGGC GATGCTGGAC GCGGGGCGTT GTACTTTCTA CACCCCGGCA TCGCTGGGAG ATGTGAAACT GGAACTTTTT GCGGTGCTGC GGACA